7 Direct Approaches to Continuous Optimal Control
Come from Chapter 13 in Numerical Optimal Control by Moritz Diehl and Sebastien Gros
Direct methods to continuous optimal control finitely parameterize the infinite dimensional decision variables, notably the controls
The direct approach connects easily to all optimization methods developed in the continuous optimization community. Most successful direct methods even parameterize the problem such that the resulting NLP has the structure of a discrete time optimal control problem, such that all the techniques and structures about dynamic programming are applicable. For this reason, the current chapter is kept relatively short; its major aim is to outline the major concepts and vocabulary in the field.
We start by describing direct single shooting, direct multiple shooting, and direct collocation and a variant pseudospectral methods. We also discuss how sensitivities are computed in the context of shooting methods. The optimization problem formulation we address in this chapter typically read as (but are not limited to):
For many optimal control problems (OCPs), the system state derivatives
7.1 Direct Single Shooting
All shooting methods use an embedded ODE or differential algebraic equations (DAE) solver in order to eliminate the continuous time dynamic system. They do so by first parameterizing the control function
The most widespread parameterization are piecewise constant controls, for which we choose a fixed time grid
Thus, the dimension of the vector
Single shooting is a sequential approach that calculate OCP recursively. In single shooting, we regard the states
In order to discretize inequality path constraints, we choose a grid, typically the same as for the control discretization, at which we check the inequalities. Thus, in single shooting, we transcribe the optimal control problem into the following NLP, that is visualized in Figure 13.1.
NLP structure in single shooting
As the only variable of this NLP is the vector SQP) is used, e.g. the codes NPSOL or SNOPT. Let us first assume the Hessian needs not be computed but can be obtained e.g. by Broyden-Fletcher-Goldfarb-Shanno (BFGS) updates.
The computation of the derivatives can be done in different ways with a different complexity:
first, we can use forward derivatives, using finite differences or algorithmic differentiation. Taking the computational cost of integrating one time interval as one computational unit, this means that one complete forward integration costs
Second, if the number of output quantities such as objective and inequality constraints is not big, we can use the principle of reverse automatic differentiation in order to generate the derivatives. In the extreme case that no inequality constraints are present and we only need the gradient of the objective, this gradient can cheaply be computed by reverse Algorithmic Differentiation (AD), as done in the so called gradient methods. Note that in this case the same adjoint differential equations of the indirect approach can be used for reverse computation of the gradient, but that in contrast to the indirect method we do not eliminate the controls, and we integrate the adjoint equations backwards in time. The complexity for one gradient computation is only
Third, in the case that we have chosen piecewise controls, as here, we might use the fact that after the piecewise control discretization we have basically transformed the continuous time OCP into a discrete time OCP (see next section). Then we can compute the derivatives with respect to both
Example 7.1
OCP formulation
Let us illustrate the single shooting method using the following simple OCP:
The resulting solution is illustrated in Figure 13.1, together with the sparsity patterns of the Jacobian of the inequality constraint function, i.e.
and the one of the Hessian of the Lagrange function.
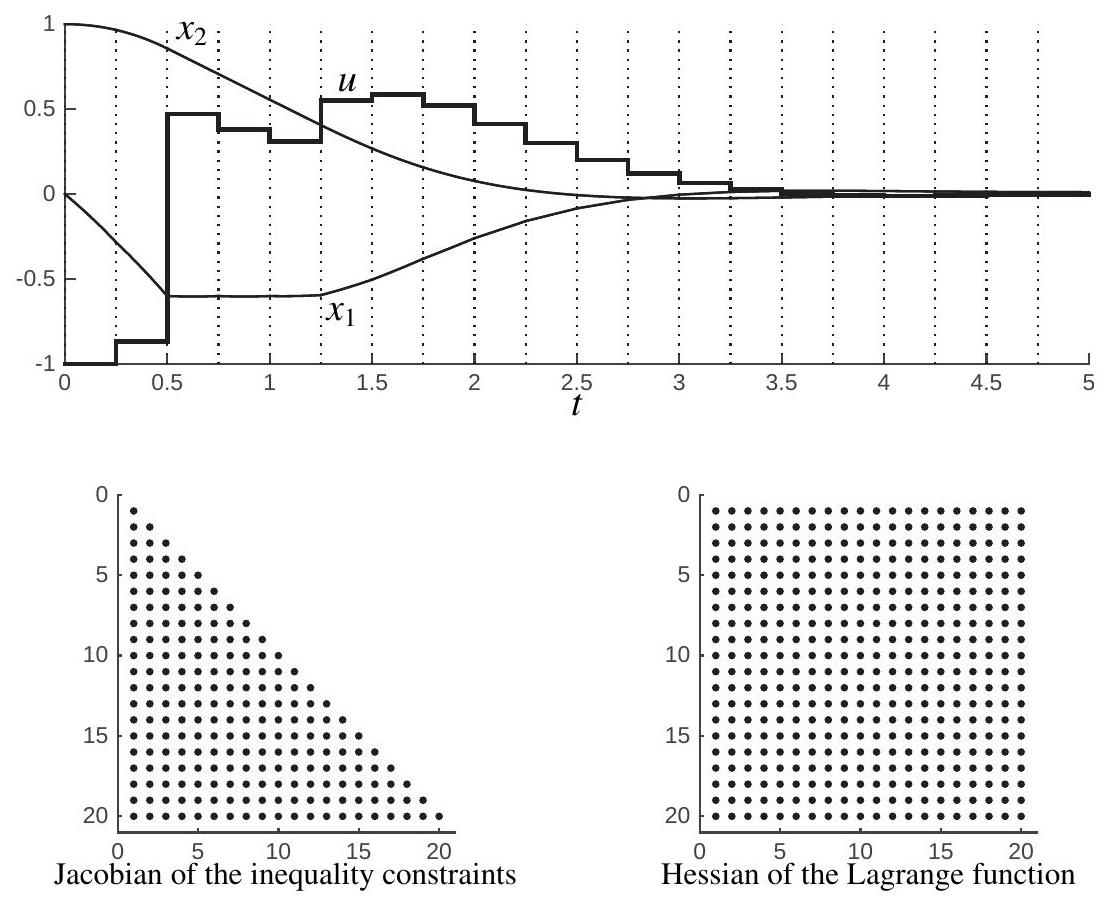
Figure 13.1: Solution to OCP (13.1) using a discretization based on single shooting, with
Nonlinearity propagation in direct single shooting
Unfortunately, direct single shooting often suffers from ill-conditioned problem. More specifically, when deploying single shooting in the context of direct optimal control a difficulty can arise from the nonlinearity of the "simulation" function
where
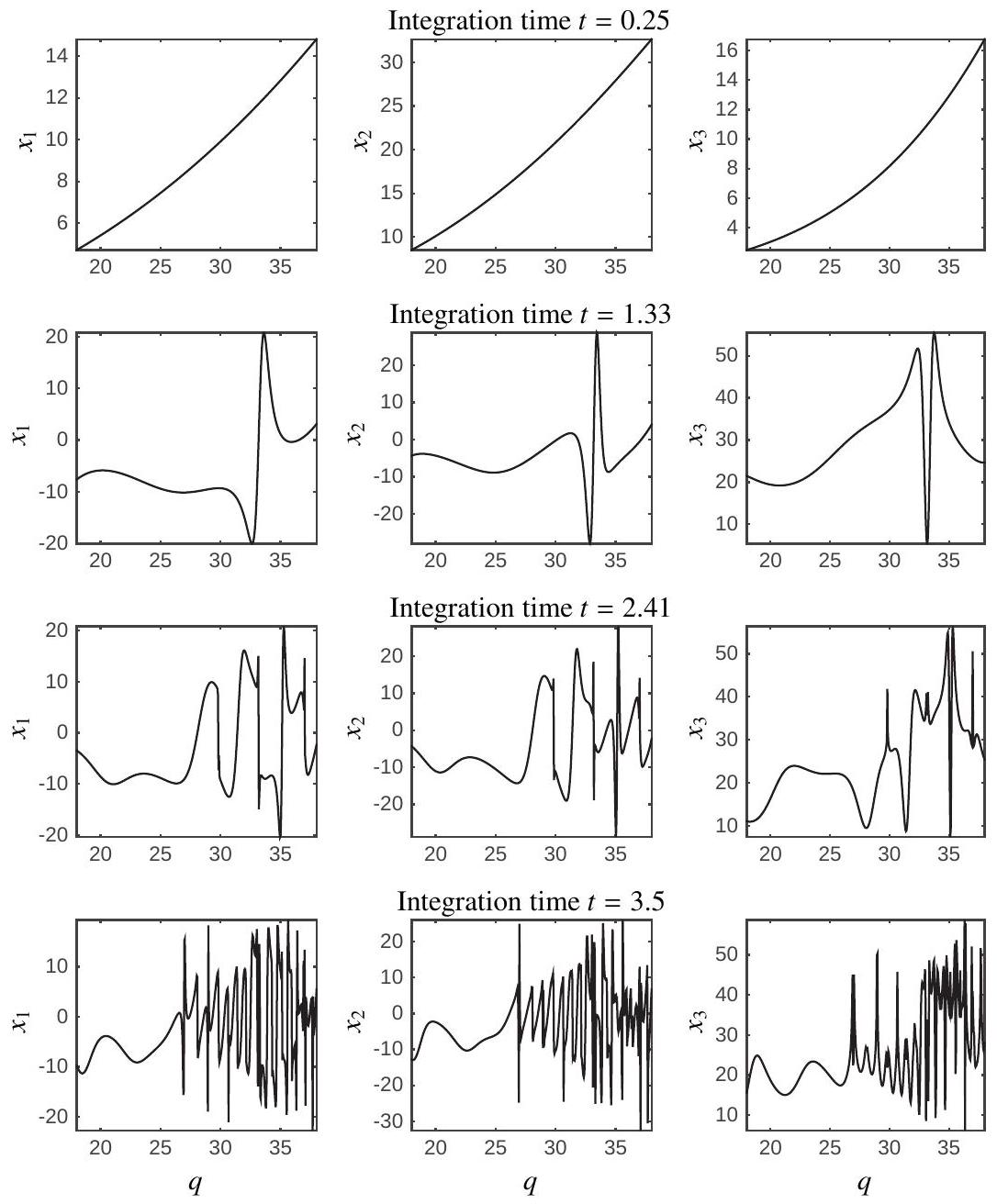
Figure 13.2: Illustration of the propagation of nonlinearities in the simple dynamic system (13.2). One can observe that for a short integration time
This example ought to warn the reader that the function
These observations entails that in practice, when using single-shooting, a very good initial guess for
7.2 Direct Multiple Shooting
The direct multiple shooting method was originally developed by Bock and Plitt. It follows similar ideas as the indirect multiple-shooting approach, but recast in the direct optimization framework, where the input profile is also discretized and part of the decision variables.
The idea behind the direct multiple-shooting approach stems from the observation that performing long integration of dynamics can be counterproductive for discretizing continuous optimal control problems into NLPs, and tackles the problem by limiting the integration over arbitrarily short time intervals. Direct multiple-shooting performs first a finite-dimensional discretization of the continuous control input
In contrast to single shooting, it then solves the ODE separately on each interval
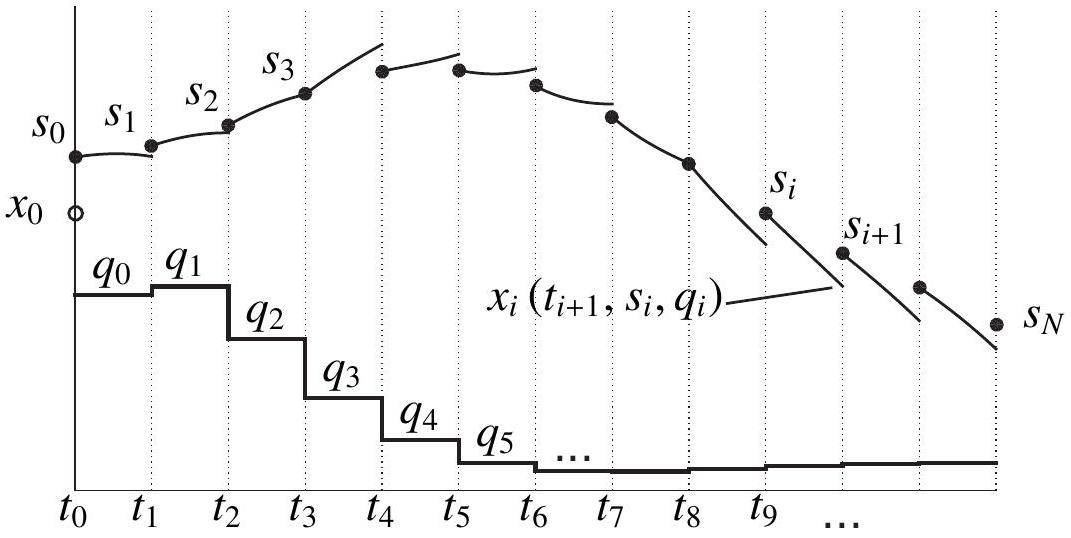
Figure 13.3: Illustration of the direct multiple shooting method. A piecewiseconstant input profile parametrized by
See Figure 13.3 for an illustration. Thus, we obtain trajectory pieces
The problem of piecing the trajectories together, i.e. ensuring the continuity condition
Finally, we choose a time grid on which the inequality path constraints are checked. It is common to choose the same time grid as for the discretization of the controls as piecewise constant, such that the constraints are checked based on the artificial initial values
The NLP arising from a discretization of an OCP based on multiple shooting typically reads as:
It is visualized in Figure 13.3. Let us illustrate the multiple shooting method using the OCP
and the constraints are also ordered in time. The resulting solution is illustrated in Figure 13.4, together with the sparsity patterns of the Jacobian of the equality constraint function, and the one of the Hessian of the Lagrange function.
Most important, the sparsity structure arising from a discretization based on multipleshooting (see Figure 13.4 for an illustration) ought to be exploited in the NLP solver.
Example 13.2
Let us tackle the OCP (13.1) of Example 13.1 via direct multipleshooting. A 4-step RK4 integrator has been used here, deployed on
and the shooting constraints are also imposed time-wise.
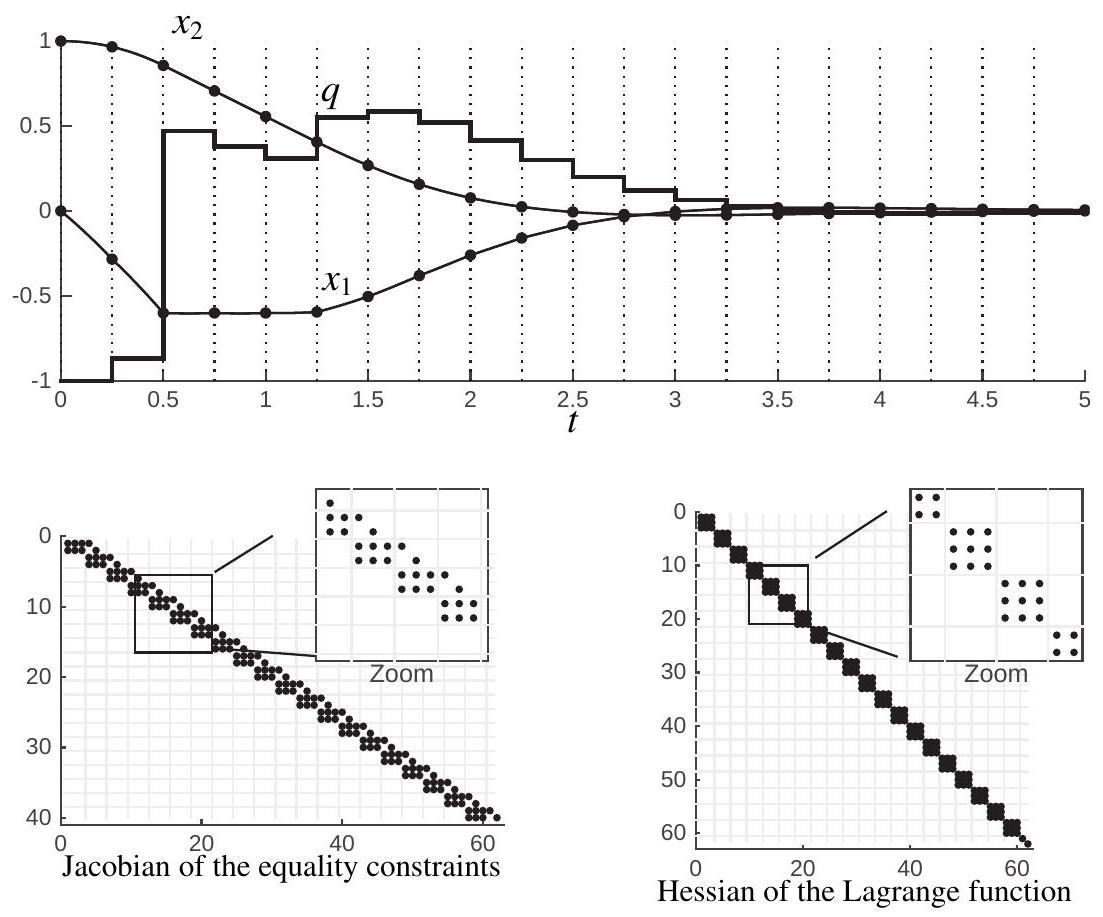
Figure 13.4: Solution to OCP
The resulting solution is displayed in Figure 13.4, where one can observe the discrete state trajectories (black dots) at the discrete time instants
Remark on Schlöder's Reduction Trick
We point out here that the derivatives of the condensed QP could also directly be computed, using the reduced way, as explained as first variant in the context of single shooting. It exploits the fact that the initial value
The main advantages of lifted Newton approaches such as multiple shooting compared with single shooting are the facts that
- we can also initialize the state trajectory,
- they show superior local convergence properties in particular for unstable systems. An interesting remark is that if the original system is linear, continuity is perfectly satisfied in all SQP iterations, and single and multiple shooting would be identical. Also, it is interesting to recall that the Lagrange multipliers
for the continuity conditions are an approximation of the adjoint variables, and that they indicate the costs of continuity.
Finally, it is interesting to note that a direct multiple shooting algorithm can be made a single shooting algorithm easily: we only have to overwrite, before the derivative computation, the states
7.3 Direct Collocation method
A third important class of direct methods are the so-called direct transcription methods, most notably direct collocation. The discretization method applied here is directly inspired from the collocation-based simulation, and very similar to the indirect collocation method.
Here we discretize the infinite OCP in both controls and states on a fixed and relatively fine grid
On each collocation interval
The collocation-based integration of the state dynamics on a time interval
for the variables
We now turn to building the NLP based on direct collocation. In addition to solving the collocation equations
holds for
One finally ought to approximate the integrals
It is interesting to observe, that an arbitrary sampling of the state dynamics is possible by enforcing the path constraints at arbitrary time points
Direct Collocation yields a large scale but sparse NLP, which can typically be written in the form
One ought to observe that the discrete state variables
We illustrate the variables and constraints of NLP (13.5) in Figure 13.5.
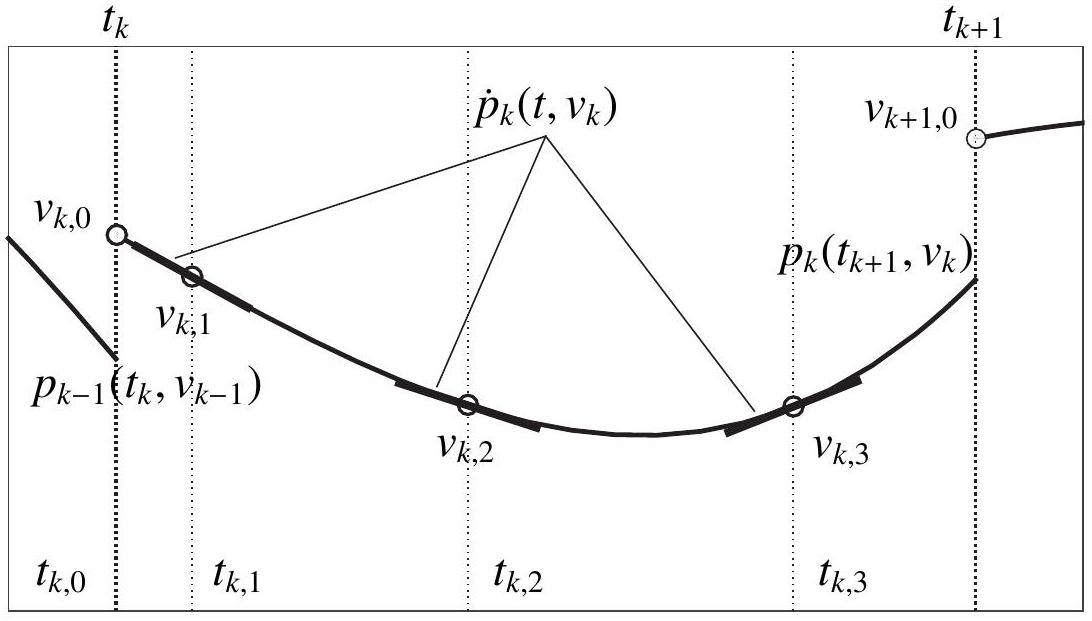
Figure 13.5: Illustration of the variables and constraints of NLP (13.5) for
The direct collocation method offers two ways of increasing the numerical accuracy of the integration. We need to remember here that the integration error of a Gauss-Legendre collocation scheme is of
One ought to observe here that discretizing an OCP using direct collocation allows for a fairly straightforward construction of the exact Hessian of the NLP. Indeed, one can observe that the nonlinear contributions to the constraints involved in the NLP arising from a discretization based on direct collocation are all explicitly given by the model continuous dynamics function
Example 13.3
Let us tackle the OCP (13.1) of Example 13.1 via direct collocation. The direct collocation is implemented using a Gauss-Legendre direct collocation scheme with
In this example, the variables are ordered in time as:
where
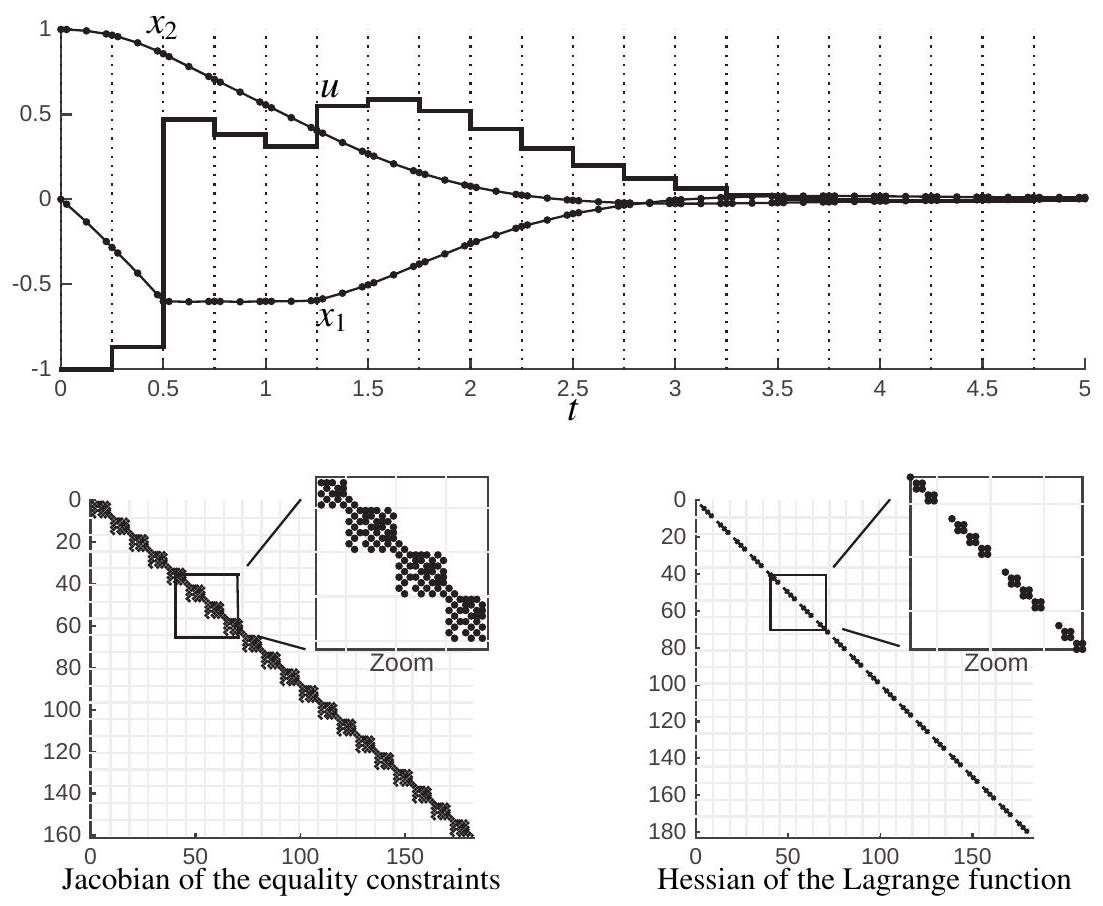
Figure 13.6: Solution to OCP
The large NLP resulting from direct collocation need to be solved by structure exploiting solvers, and due to the fact that the problem functions are typically relatively cheap to evaluate compared to the cost of the linear algebra, nonlinear interior point methods are often the most efficient approach here. A widespread combination is to use collocation with IPOPT using the AMPL interface, or the casADi tool. It is interesting to note that, like in direct multiple shooting, the multipliers associated to the continuity conditions are again an approximation of the adjoint variables.
An interesting variant of orthogonal collocation methods that is often called the pseudo-spectral optimal control method uses only one collocation interval but on this interval it uses an extremely high order polynomial. State constraints are then typically enforced at all collocation points. Unfortunately, the constraints Jacobian and Lagrange Hessian matrices arising from the pseudospectral method are typically fairly dense and therefore more expensive to factorize than the ones arising in direct collocation.
Alternative input parametrization
We have discussed to far the use of a piecewise-constant input parametrization in the context of direct methods. We ought to stress here that, while this choice is simple and very popular, it is also arbitrary. In fact, what qualifies direct methods is their use of a restriction of the continuous (and therefore
In the context of direct collocation, a fairly natural refinement of the continuous input parametrization consists in providing as many DoF as the discretization of the optimal control problem allows. More specifically, one can readily observe that the standard piecewise input parametrization is enforced by construction of the collocation equations
and the NLP receives the decision variables
It is important to observe here that the input is parametrized as
7.4 A Classification of Direct Optimal Control Methods
It is an interesting exercise to try to classify Newton type optimal control algorithms. Let us have a look at how nonlinear optimal control algorithms perform their major algorithmic components, each of which comes in several variants:
- Treatment of Inequalities: Nonlinear integer program (IP) vs. SQP.
- Nonlinear Iterations: Simultaneous vs. Sequential.
- Derivative Computations: Full vs. Reduced.
- Linear Algebra: Banded vs. Condensing.
In the last two of these categories, we observe that the first variants each exploit the specific structures of the simultaneous approach, while the second variant reduces the variable space to the one of the sequential approach. Note that reduced derivatives imply condensed linear algebra, so the combination [Reduced,Banded] is excluded. In the first category, we might sometimes distinguish two variants of SQP methods, depending on how they solve their underlying QP problems, via active set QP solvers (SQP-AS) or via interior point methods (SQP-IP).
Based on these four categories, each with two alternatives, and one combination excluded, we obtain 12 possible combinations. In these categories, the classical single shooting method could be classified as [SQP, Sequential, Reduced] or as [SQP, Sequential, Full, Condensing] because some variants compute directly the reduced derivatives