1 Introduction
This first 5 parts refers this e-book: An Introduction to Mathematical Optimal Control Theory by Lawrence C. Evans in 2024. The Chapter 6 (differential game) and 7 (stochastic control) of this e-book are not contained This 6th part is the note from various notes online
1.1 basic problem
DYNAMICS: Consider an ODE:
: initial point : dynamic function : unknown; dynamic evolution of the state of some "system"
CONTROLLED DYNAMICS: Generalize a bit,
Change the value
Then the dynamic equation becomes:
We call a function
Notation
Introduce:
To denote the collection of all admissible controls
would be more precise
Payoffs
Overall task will be to determine what is the "best" control for our system. For this we need to specify a specific payoff (or reward) criterion. Let us define the payoff functional
where:
solves ODE for the control : Given; runnig payoff : Given; terminal payoff; : Given; terminal time
The basic problem
Aim: find a control
for all controls
This task presents us with these mathematical issues:
- Does an optimal control exist?
- How can we characterize an optimal control mathematically?
- How can we construct an optimal control?
These turn out to be sometimes subtle problems, as the following collection of examples illustrates.
1.2 Examples
Example 1: Control of Production and Consumption
Suppose we own, say, a factory whose output we can control. Let us begin to construct a mathematical model by setting
We suppose that we consume some fraction of our output at each time, and likewise can reinvest the remaining fraction. Let us denote:
This will be our control, and s.t. the obvious constraint that:
The corresponding dynamic equation is:
The constant
Take as a payoff functional:
That means we want to maximize our total consumption of the output, our consumption at a given time t being
In 4.4.2, we will see that the optimal control is
In other words, we should reinvest all the output (and therefore consume nothing) up until time
Example 2: Reproduction Strategies in Social Insects
In this example, we consider a population of social insects, a population if bees. Write
number of workers at time number of queens fraction of colony effort devoted to increasing work force
Constraint of
Introduce the dynamic for the numbers of workers and the number of queens:
- workers:
:is the death rate of workers; given constant : the known rate at which each worker contributes to the bee economy
- queens:
constant
Goal: maximize the queens at time
We have
answer will again turn out to be a bang–bang control
Example 3: A Pendulum
A hanging pendlum:
If no external force:
The solution will be a damped oscillation, provided
Let
Our dynamics now become
Define
We introduce as well
for
Maximize
The terminal time isn't fixed, but rather depends upon the control. This's a fixed endpoint, free time problem.
Example 4: A Moon Lander
This model asks us to bring a spacecraft to a soft landing on the lunar surface, using the least amount of fuel.
Introduce the notation:
Notation
: height at time : velocity : mass of spacecraft at time (changing as fuel is burned) : thrust at time t, assumed that
For Newton's law:
Modelled by ODE:
We want to minimize the amount of fuel used up, that is, to maximize the amount remaining once we have landed. Thus
where
We have also the extra constraints
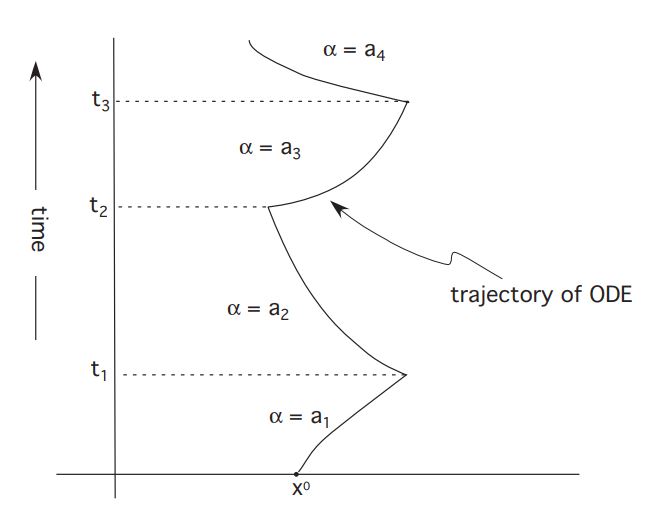
Example 5: Rocket Railroad Car
Imagine a railroad car powered by rocket engines on each side. We introduce the variables:
: position at time : velocity at time : thrust from rockets at time , assumed that
We want to figure out how to fire the rockets, so as to arrive at the origin 0 with zero velocity in a minimum amount of time. Assuming the car has mass
Rewrie by setting
Take
for
1.3 A geometric solution
Introduce some ad hoc calculus and geometry methods for the rocke car problem.
First of all, let us guess that to find an optimal solution we will need only to consider the cases
CASE 1:
Then
And so
Let
belong to the time interval where and interate from to : Then
In other words, so long as the control is set for
, the trajectory stays on the curve for some constant . 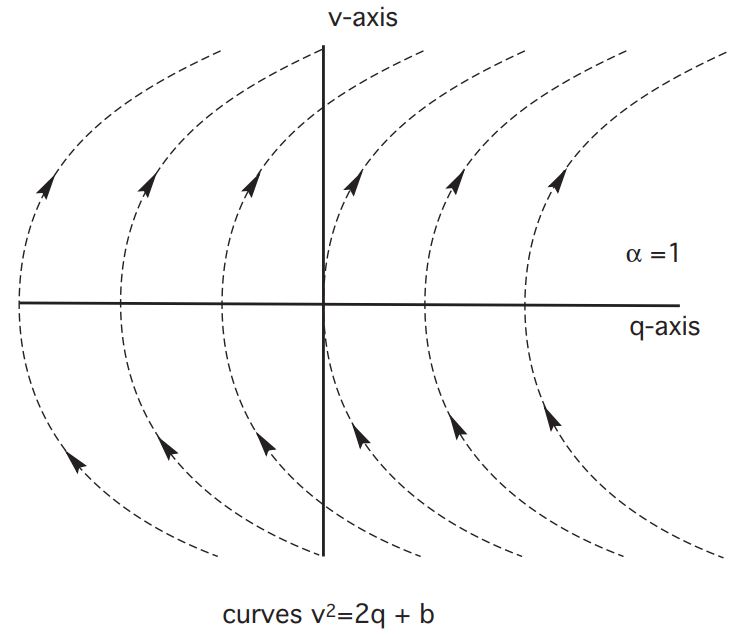
CASE 2:
Then
Let
As long as the control is set for
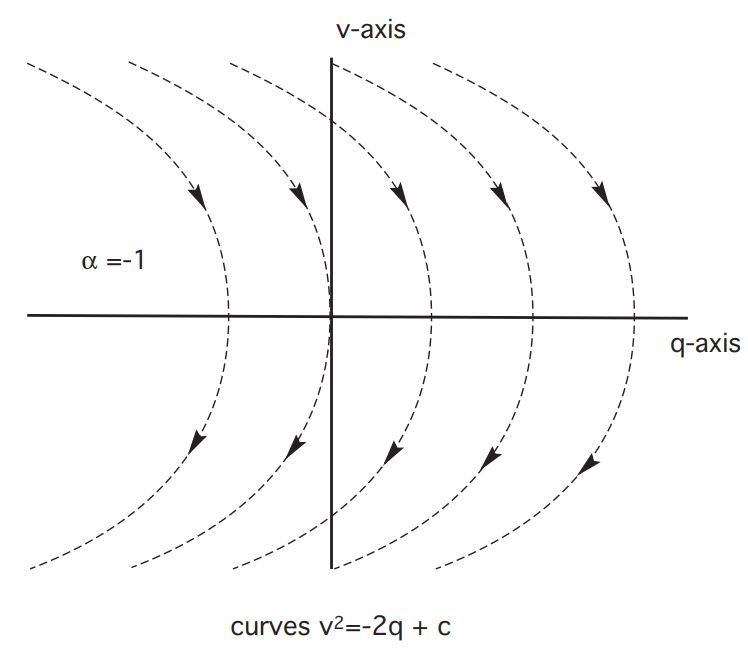
Geometric interpretation
Now we can design an optimal control
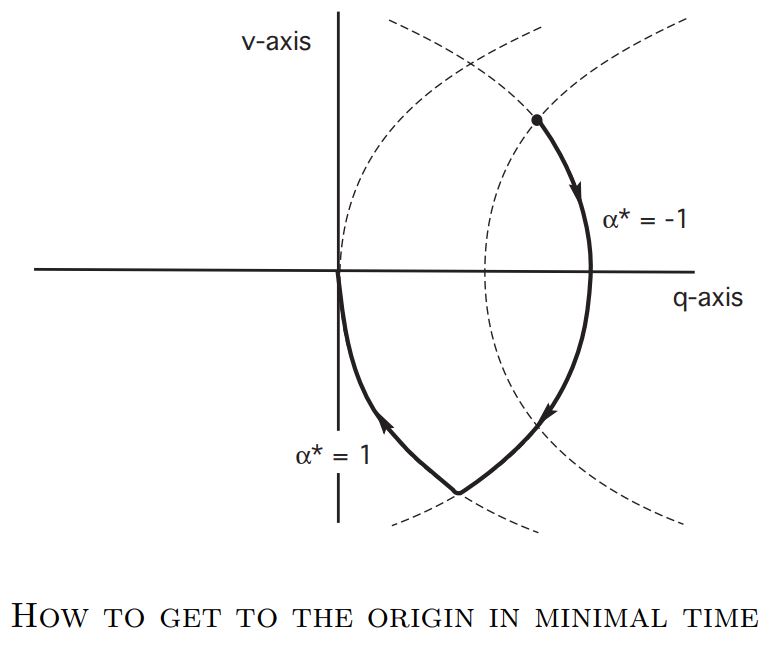
1.4 Optimal Control Solutions
3-Direct method (Single/Multiple shooting, collocation method) - Zhuanlan in Zhihu including Numerical Optimal Control by Moritz Diehl and Sebastien Gros, which is the reference e-book in 1.4.
There are 3 basic families of approaches to address continuous-time optimal control problems (OCP):
- State-space approaches: Hamilton-Jacobian-Bellman (
HJB) Equation (Dynamic Programmingfor discrete);- Core: states that each subarc of an optimal trajectory must be optimal
- Use the principle of optimality:
- A PDE in the state space
- Methods to numerically compute solution approximations exist
- but the approach severely suffers from Bellman’s “curse of dimensionality”, thus restricted to small state dimensions
- Core: states that each subarc of an optimal trajectory must be optimal
- Indirect Methods: Pontryagin Maximum Principle (
PMP);- Core: derive a Boundary Value Problem (BVP) in ODE
- Use the necessary conditions of optimality of the infinite dimensional problem:
- This BVP must numerically be solved
- first optimize, then discretize
- the conditions of optimality are first written in continuous time for the given problem, and then discretized in one way or another in order for computing a numerical solution
- numerical solution of the BVP: shooting techniques or by collocation
- 2 major drawbacks:
- the underlying differential equations are often difficult to solve due to strong nonlinearity and instability, and that changes in the control structure, i.e. the sequence of arcs where different constraints are active, are difficult to handle: they usually require a completely new problem setup
- on so-called singular arcs, higher index differential-algebraic equations (DAE) arise which necessitate specialized solution techniques
- 2 major drawbacks:
- Core: derive a Boundary Value Problem (BVP) in ODE
- Direct Methods:
- Core: Transform the original infinite-dimensional OCP into a finite-dimensional NonLinear Program (NLP)
- solved by structure-exploiting numerical optimization methods
- first discretize, then optimize
- the problem is first converted into a discrete one, on which optimization techniques are then deployed
- Advantages over indirect ones: they can easily treat all sorts of constraints, such as e.g. the inequality path constraints in one formulation
- the activation and de-activation of the inequality constraints, i.e. structural changes in active constraints, occurring during the optimization procedure are treated by well-developed NLP methods that can efficiently deal with such active set changes
- All direct methods are based on one form or another of finite-dimensional parameterization of the control trajectory, but differ significantly in the way the state trajectory is handled
- For solution of constrained optimal control problems in real world applications, direct methods are nowadays by far the most widespread and successfully used techniques
- Direct Single Shooting
- Direct Multiple Shooting
- Direct Collocation