5 Dynamic Programming
5.1 Derivation of Bellman's PDE
5.1.1 Dynamic Programming
We begin with some mathematical wisdom:
“It is sometimes easier to solve a problem by embedding it within a larger class of problems and then solving the larger class all at once.”
A Calculus Example
Suppose we wish to calculate the value of the integral
This is pretty hard to do directly, so let us as follows add a parameter
We compute
where we integrated by parts twice to find the last equality. Consequently
and we must compute the constant
and so
Come back to control
We want to adapt some version of this idea to the vastly more complicated setting of control theory. For this, fix a terminal time
with the associated payoff functional
We embed this into a larger family of similar problems, by varying the starting times and starting points:
with
Consider the above problems for all choices of starting times
Definition: value function
For
Notice then that
5.1.2 Derivation of Hamilton-Jacobi-Bellman Equation
Our first task is to show that the value function
Our derivation will be based upon the reasonable principle that
"it's better to be smart from the beginning, than to be stupid for a time and then become smart".
We want to convert this philosophy of life into mathematics.
To simplify, we hereafter suppose that the set
Theorem 5.1 (Hamilton-Jacobi-Bellman Equation)
Assume that the value function
with the terminal condition
Remark
We call
for the partial differential equations Hamiltonian
where
Proof
- Let
and let be given. As always
Pick any parameter
for times
What is the payoff of this procedure? Now for times
The payoff for this time period is
But the greatest possible payoff if we start from (
- We now want to convert this inequality into a differential form. So we rearrange
and divide by :
Let
But
Employ this above, to discover:
This inequality holds for all control parameters
- We next demonstrate that in fact the maximum above equals zero. To see this, suppose
were optimal for the problem above. Let us utilize the optimal control for . The payoff is
and the remaining payoff is
Rearrange and divide by
Let
and therefore
for some parameter value
5.1.2 The Dynamic Programming Method
Here is how to use the dynamic programming method to design optimal controls:
Step 1: Solve the Hamilton-Jacobi-Bellman equation, and thereby compute the value function
Step 2: Use the value function
to be a parameter value where the maximum in (HJB) is attained. In other words, we select
Next we solve the following ODE, assuming
Finally, define the feedback control
In summary, we design the optimal control this way: If the state of system is
We demonstrate next that this construction does indeed provide us with an optimal control.
Theorem 5.2 (Verification of Optimality)
The control
Proof of Theorem 5.2
We have
Furthermore according to the definition
That is,
and so
5.2 Examples
5.2.1 Example 1: Dynamics with Three Velocities
Let us begin with a fairly easy problem:
where our set of control parameters is
We want to minimize
and so take for our payoff functional
As our first illustration of dynamic programming, we will compute the value function
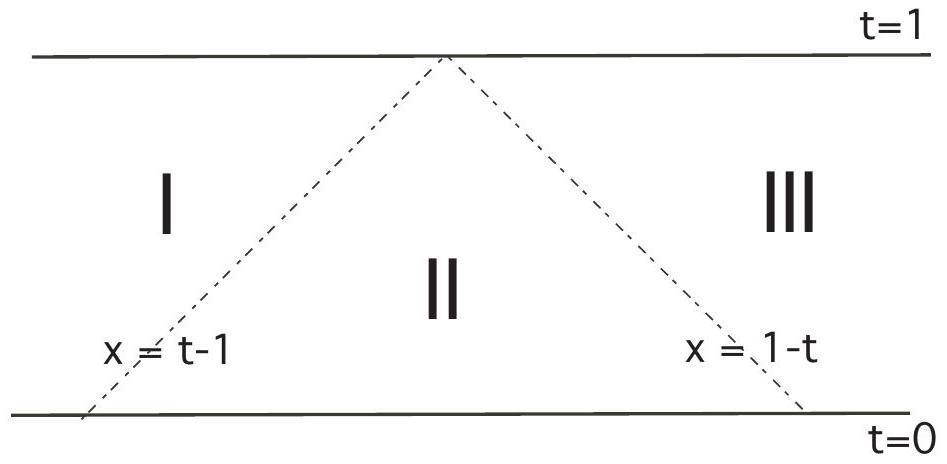
- Region
. - Region
. - Region
.
We will consider the three cases as to which region the initial data (
- Region III
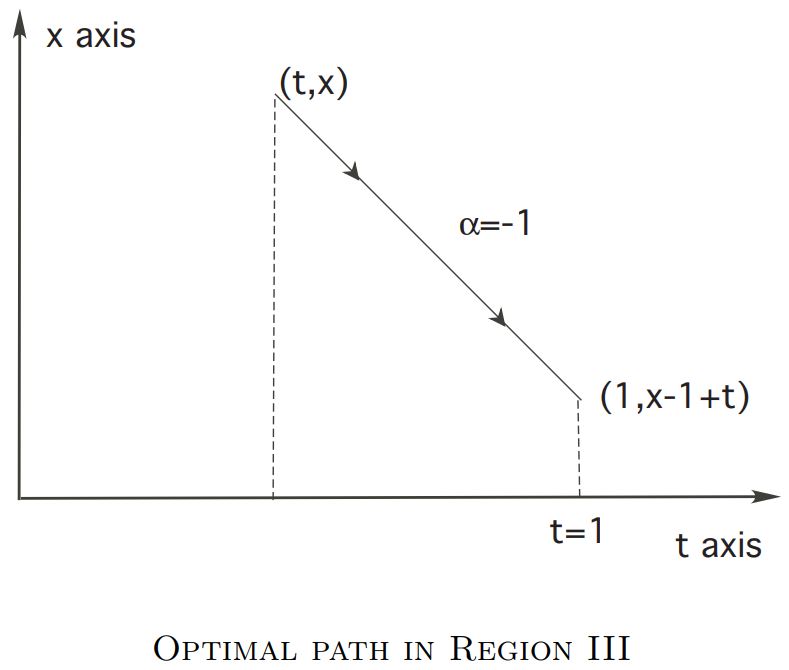
In this case we should take
Region I In this region, we should take
, in which case we can similarly compute . Region II In this region we take
, until we hit the origin, after which we take . We therefore calculate that in this region.
Checking the Hamilton-Jacobi-Bellman PDE
Now the Hamilton-JacobiBellman equation for our problem reads
for
and so
We must check that the value function
Now in Region II
in accordance with
and therefore
Hence
because
Likewise the Hamilton-Jacobi-Bellman PDE holds in Region I.
Remarks
- In the example,
is not continuously differentiable on the borderlines between Regions II and I or III. - In general, it may not be possible actually to find the optimal feedback control. For example, reconsider the above problem, but now with
. We still have , but there is no optimal control in Region II.
5.2.2 Example 2: Rocket Railroad Car
Recall that the equations of motion in this model are
and
To use the method of dynamic programming, we define
What is the Hamilton-Jacobi-Bellman equation? Note
for
Hence our PDE reads
and consequently
Checking the Hamilton-Jacobi-Bellman PDE
We now confirm that
A direct computation, the details of which we omit, reveals that
In Region I we compute
and therefore
This confirms that our
Optimal control
Since
the optimal control is
5.2.3 Example 3: General Linear-Quadratic Regulator
For this important problem, we are given matrices
and
We take the linear dynamics
for which we want to minimize the quadratic cost functional
So we must maximize the payoff
The control values are unconstrained, meaning that the control parameter values can range over all of
We will solve by dynamic programming the problem of designing an optimal control. To carry out this plan, we first compute the Hamilton-Jacobi-Bellman equation
where
Rewrite:
We also have the terminal condition
Maximization
For what value of the control parameter
Therefore
This is the formula for the optimal feedback control: It will be very useful once we compute the value function
Finding the value function
We insert our formula
Our next move is to guess the form of the solution, namely
provided the symmetric
Now, since
Next, compute that
We insert our guess
Look at the expression
Then
This identity will hold if
In summary, if we can solve the Riccati equation
Furthermore,
5.2.4 Example 4: More General Linear-Quadratic Regulator with Cross-Term and time-variant
Chapter 11, part 2 in Numerical Optimal Control by Moritz Diehl and Sebastien Gros.
For this important problem, we are given matrices
and
We take the linear dynamics
for which we want to minimize the quadratic cost functional
So we must maximize the payoff
as
Also, we start from the assumption that the value function is quadratic. In order to verify this statement, let us first observe that
Introduce Schur complement lemma below:
Lemma: Schur Complement
If a matrix
and the minimizer
By Schur Complement Lemma, the above HJB eqatio yields
which is again a quadratic term. Thus, as
with terminal condition
is called the differential Riccati equation. Integrating it backwards allows us to compute the cost-to-go function for the above optimal control problem. The corresponding feedback law is by the Schur complement lemma given as:
5.3 Dynamic Programming and the Pontryagin Maximum Principle
5.3.1 The Method of Characteristics.
Assume
A basic idea in PDE theory is to introduce some ordinary differential equations, the solution of which lets us compute the solution
This section discusses this method of characteristics, to make clearer the connections between PDE theory and the Pontryagin Maximum Principle.
Notaion
Derivation of characteristic equations
We have
and therefore
Now suppose
Let
We can simplify this expression if we select
then
These are Hamilton's equations, already discussed in a different context in §4.1:
We next demonstrate that if we can solve
Note also
This gives us the solution, once we have calculated
5.3.2 Connections between Dynamic Programming AND The Pontryagin Maximum Principle
Return now to our usual control theory problem, with dynamics
and payoff
As above, the value function is
The next theorem demonstrates that the costate in the Pontryagin Maximum Principle is in fact the gradient in
Theorem 5.3 (Costates AND Gradients)
Assume
If the value function
Proof
- As usual, suppress the superscript *. Define
. We claim that satisfies conditions and of the Pontryagin Maximum Principle. To confirm this assertion, look at
We know
and, applying the optimal control
- Now freeze the time
and define the function
Observe that
Substitute above:
Recalling that
Recall also
Hence
which is
and maximum occurs for
and this is assertion (M) of the Maximum Principle.
Interpretations
The foregoing provides us with another way to look at transversality conditions:
- Free endpoint problem: Recall that we stated earlier in Theorem 4.3 that for the free endpoint problem we have the condition
for the payoff functional
To understand this better, note
- Constrained initial and target sets:
Recall that for this problem we stated in Theorem 4.5 the transversality conditions that
when
with the constraint that we start at
this means that
5.4 Infinite Time Optimal Control
Let us now regard an infinite time optimal control problem, as follows:
with the associated payoff functional
The principle of optimality states that the value function of this problem, if it is finite and it exists, must be stationary, i.e. independent of time. Setting
with stationary optimal feedback control law
This equation is easily solvable in the linear quadratic case, i.e., in the case of an infinite horizon linear quadratic optimal control with time independent cost and system matrices. The solution is again quadratic and obtained by setting
and solving
This equation is called the algebraic Riccati equation in continuous time. Its feedback law is a static linear gain: