Sensor Integration and Signal processing Part II
Average filter
Average is sum of a given data set divided by the number of data in it.
For example,If the given data set contains
The expression above treats whole data in a single batch and thus called 'batch expression'.
The recursive expression boosts computational efficiency by reusing prior results (notably for large datasets) and cuts memory usage, needing only the previous average, new data, and total data count, unlike Average Filter which requires the full dataset.
For the averaging filter, we can get the following recursive expression.
If we use the Equation above to get average, only the average computed in previous step(
This equation could be simplified even further. If we define
And we can get a simplified form of the recursive expression:
The name of this Equation is 'average filter'.
The average filter is applicable to both average calculation and sensor initialization, as perfectly exemplified by a digital weight scale.
- The zero point of a digital weight scale changes continuously for various reasons, so an initialization process is required to determine the zero point by collecting measurements over a certain period after power-on. If all measurements have to be stored to calculate the average, an expensive microprocessor will be needed, which is obviously an unfavorable option. This can be avoided by adopting an average filter.
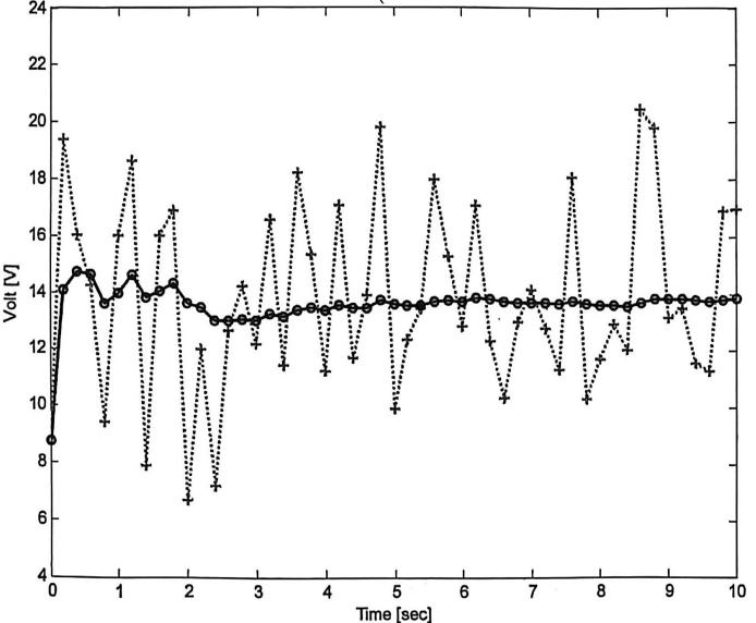
The plot of the average filter's voltage results shows violent fluctuations in raw measurements versus a stable filtered output. As data accumulates, noise fades and the output approaches the true voltage average; this noise-filtering property of averaging is why it is named a "filter".
Moving average filter
5-day moving average curve plots the moving average of stock prices over a 5-day window, which is used to track the medium-to-long-term trends of stock prices and eliminate confusion caused by daily fluctuations. This chapter will elaborate on the concept of the moving average.
Moving average is an average of not all the data in the data set, but of certain number of recent measurements. This method discards the oldest data whenever a new datum comes in and in that way it maintains the number of datum to get the average.
Moving average of
Beware that
Leaving
This is 'moving average filter'. It is not as neat as average filter but still is in recursive expression.
Load required for computation of an average is not increased even after a new datum is fed in. This inherent characteristic of low computing load gives little room for recursive expression to provide any advantage unlike average filter.
The moving average filter involves a direct trade-off between noise reduction and phase lag. While increasing the sample size (
In practice, the value of
- For rapid variations: Use a smaller
to minimize lag and ensure quick tracking. - For slow variations: Use a larger
to maximize noise reduction and achieve a stable average.
The Moving Average Filter involves a fundamental trade-off between noise suppression and response time:
- Higher
: Enhances noise reduction but introduces latency, hindering real-time tracking. - Lower
: Enables faster response to data changes but sacrifices filtering quality.
Conclusion: The optimal value for
1st order Low-pass filter
When moving average filter is brought into real world, you will notice that reducing noise and tracking variation of the given data at the same time is not an easy task. Quite frequently, even if you change the number of datum to get average, the result is not so satisfactory.
Breaking the definition of moving average in Equation into each term.
From this expression, we see that each term in the moving average has same weighting (
An aircraft has an attitude sensor which returns 50 measurements in 1 second. Moving average filter of the flight management computer computes an average with 50 collected datum(
The answer would most possibly be the one measured most recent. However, moving average filter processes all measurements with equal weighting.
Unlike we have done so far, recursive expression will be directly given for low-pass filter. The accurate name for this filter is '1st order low-pass filter'.
Where
From now on, we will use the term 'estimate' instead of 'average' or 'mean' because
Thus:
Therefore, there are following relationships among measurements:
Equation confirms that weighting coefficients decrease as data ages. Consequently, older data points exert less influence on the final estimate, ensuring the filter prioritizes recent information.
The estimate of a 1st-order low-pass filter is highly sensitive to the coefficient
- Small
(e.g., ): Higher noise levels but faster response with minimal lag. - Large
(e.g., ): Superior noise reduction at the cost of significant time delay.
1st order low-pass-filter is also known as 'exponentially weighted moving average filter'.
Kalman filter algorithm
It receives only one input (measurement,
Internal process is done through a four-step computation.
- Step I (Prediction): Computes predicted variables (denoted by a - superscript) based on the system model.
- Step II (Kalman Gain): Calculates the Kalman gain using the output from Step I and external presets/noise characteristics (H and R).
- Step III (Estimation): Computes the current estimate using the measurement input and Step I's prediction (conceptually similar to a low-pass filter).
- Step IV (Error Covariance): Computes the error covariance to evaluate the estimate's accuracy and determine its reliability.
The Kalman filter can be distilled into a continuous recursive loop comprising two main phases: Prediction and Estimation.
- Prediction Process (Step I): Utilizes the previous state and system parameters (
and ) to compute the predicted state ( and ). - Estimation Process (Steps II-IV): Incorporates the current measurement (
) alongside parameters ( and ) to compensate for prediction errors, yielding the final optimal estimate ( ).
Summary: The algorithm operates as a simple closed loop: Predict state → Compensate with measurement → Repeat.
There was a reason why low-pass filter has been mentioned so frequently whenever Kalman filter was brought up. Let us look at the expression for computing an estimate in Step III for examination.
where
Simply change:
Compare this expression with Equation, which is for computation of an estimate in Kalman filter.
Kalman filter is almost the same. The way it assigns weighting is even same with the only difference lying in the fact that Kalman filter is not using the previous estimate but prediction.
For Kalman filter algorithm:
First of all, a prediction(
Now the only variable left is Kk. This is called 'Kalman gain' and if the value of this variable is known, the new estimate could be computed.
We will take a look into an error covariance which is the last step of the estimation process
Error covariance indicates the difference between the estimate from Kalman filter and the true but unknown value. In other words, error covariance is a degree of accuracy of the estimate.
If
There is a following relationship between
This basically means the variable
That is, Kalman filter computes probability distribution of the estimate of the variable
This means that if we draw the probability of the values that
Error covariance is defined as the following.
where
In the prediction procedure, how the estimate
Here,
Please pay attention to the notation for the prediction. The subscript ‘
Now let us examine the expression to compute the estimate in Kalman filter.
Unlike a 1st-order low-pass filter, the Kalman filter does not directly reuse the previous estimate (
- A Priori Estimate: The prediction (
), derived from the previous estimate before the current measurement is considered.
- A Posteriori Estimate: The final estimate (
), computed after updating the a priori estimate with the new measurement.
In the expression above,
The quality of prediction is determined by how close the system model is to the actual system and the performance of estimation is determined by the prediction.
It is not an exaggeration to say that the performance of Kalman filter is determined by system model. As we have seen so far system model is the one that is always critical.
Kalman filer deals with a linear state model like the one described in the following.
: state variable,( ) column vector : measurement,( ) column vector : state transubstantiation,( ) matrix : state-to-measurement matrix,( )matrix : state transitionnnoise,( ) column vector : measurement noise,( ) column vector
The Kalman filter models physical quantities using state-space equations and assumes all disturbances are white noise.
- State Variables (
): The physical quantities being estimated (e.g., position, velocity). - Matrix
(System Model): Describes the system's kinematics, defining how the state evolves over time. - Process Noise (
): Unpredictable physical disturbances affecting the actual system. - Matrix
(Observation Model): Maps the internal state variables to the external sensor measurements. - Measurement Noise (
): Inherent inaccuracies and errors in the sensor readings.
Step 1: The Blueprint — System Model (Matrix A)
- Concept: Imagine a car driving at a constant speed of
on a straight road. The state variable consists of the car's position and velocity. Matrix contains the fundamental equations of motion from physics: .
Step 2: Reality Hits — Process Noise (
- Concept: In reality, constant speed is impossible. A sudden gust of headwind, a pothole, or the driver lightly tapping the brakes will alter the momentum. These real-world physical disturbances affecting the system are called process noise
. - Because of the process noise
, the actual physical state deviates from our perfect blueprint. The car speeds up and slows down slightly, making the true path drift.
Step 3: Flawed Perception — Observation Matrix (
- Concept: We want to track the car, so we install a GPS. The observation matrix
defines what the sensor can actually "see" (e.g., the GPS maps the state by only reading the 'position' and ignoring the 'velocity'). However, GPS signals suffer from atmospheric interference. The inherent inaccuracies of the sensor itself are called measurement noise . - Even though the car is truly driving along the path, the GPS reports coordinates as scattered crosses. They bounce around the true position due to the measurement noise.
- The Ultimate Goal of the Kalman Filter: To look at only the scattered crosses (with
), acknowledge that the world is imperfect (with ), and use the laws of physics (Matrix ) to guess exactly where that true line is.
Noise
: covariance matrix of , ( ) diagonal matrix : covariance matrix of , ( ) diagonal matrix
Covariance matrix is defined as a matrix consisting of the variance of the variable. For example, if there are
It is desirable to define the matrices
First, the matrix
In this expression, Kalman gain decreases as
Balancing Kalman Gain (
- Mechanism: A lower Kalman gain reduces the weight given to the measurement and increases reliance on the system's prediction.
- Effect: The final estimate becomes smoother, with reduced variation, as it is less sensitive to external sensor noise.
- Tuning Tip: If you want the filter to trust its internal model more and ignore noisy measurements, increase the value of
.
Now let us take a look at an expression with the matrix
In this expression, the prediction of the error covariance increases as the matrix
Summing up, when
Compared with 1st order low-pass filter
Kalman filter computes the estimate with the following equation. When the equation is expanded, it reveals its form close to that of the 1st order low-pass filter.
In other words, Kalman filter is similar to the 1st order low-pass filer in a sense that the estimate is obtained from the sum of the prediction (
However, in Kalman filter, the weighting (
Error covariance(
There is a relationship between the estimate (
In Kalman filter algorithm, prediction process is also included. Prediction is a totally separate process from estimation and the system model is crucial for this. All it predicts are the state variables and the error covariance.
To design Kalman filter, a system model in the following form must be established first.The performance of Kalman filter varies greatly depending on how close the system model is to the actual system.
When deriving the system model, the characteristics of the associated noise must also be sought thoroughly. Noise also plays important role in Kalman filter. The noise in Kalman filter is a white noise that follows normal distribution.
Example1: train with constant velocity, position is measured
The Flaw in Basic Velocity Calculation (
- Noise Amplification: Calculating velocity by directly dividing a noisy position difference by a very small time step (
) drastically amplifies the error, resulting in massive, jagged spikes in velocity (a classic problem with numerical differentiation). - Clunky Alternatives: Traditional workarounds like moving averages or polynomial approximations are inelegant, and often yield poor fits.
- The Solution: The Kalman filter proves its true value in resolving exactly this type of noise challenge.
Designing the Kalman Filter (Train Example): The mandatory first step is deriving the system model. Since our targets are the train's dynamics, we define position and velocity as our primary state variables:
Let us set the system model for the example as following.
Where
If the definitions of the state variables are applied, the meaning becomes clear,
Let us first take a look at the expression for the position.
This expression is a mathematical description of a physical principle stating that 'current position = previous position + displacement'. This is why the system noise is not included in the expression. Now let us take a look at the expression for the velocity.
This means that the velocity of the train is affected only by the system noise (
Let us look into the measurement equation of the system model. Apply the matrix
The last remaining task for the derivation of the system model is the decision of the error covariance matrices (
If not, they should be determined based on experiment and experience. The modeling of the system noise(
If both covariance matrices are difficult to be obtained in analytical manner, they should be determined by trial and error.
Example2: train with constant velocity, velocity is measured
The previous example will be reversed. That is, estimating the position with the measured velocity.
Let us apply this to the system model and simplify. Now you will understand why the matrix
Conclusion
We have learned that Kalman filter not only removes noise but also has a capability to estimate velocity with position only. How could a Kalman filter estimate the velocity which has not been measured at all? The source of this amazing capability will be discussed here.
First, let us think about a low-pass filter. A low-pass filter does not have any assumption about the measured signal. It just applies some weights to the new measurement and the old estimate and then sums them. Therefore, estimating a physical quantity that has not been measured is basically impossible. In a low-pass filter, there is no estimate if there is no measurement.
But Kalman filter is different. It assumes that the mathematical model of the system is known. In other words, the principle the system relies on to return the estimate as an output is known. The secret of estimating the physical quantity that has not even been measured is lying here. By the system model which describes the relationship between the state variables, the state variable that has-not-been measured is estimated indirectly.
The description seems quite difficult to understand, so let us use an example.
If the velocity at present is
Likewise, Kalman filter estimates the state variable that has not been measured by utilizing the information from the system model. The Kalman filter in the example used this feature to estimate the velocity from the position. Since the velocity estimate must obey the law of physics, it is obvious that the trend of change in position is included in the estimate.
Summarizing, the capability of Kalman filter to estimate the physical quantity that has not been measured comes from the 'system model'. However, using the system model for the estimation is like using a doubleedged sword. If the system model is very different from the actual system, not only the estimate gets messed up but the Kalman filter algorithm itself could diverge and cause damage to the whole system in the extreme case.
Tacking an object in an image
A method to track an object on a two-dimensional plane with Kalman filter will be discussed. This technique is required when tracking a target on a radar scope or developing a system to track certain object through a camera in real time.
In other words, the derivation of the system model should be based on the state variables set as horizontal(x-axis) and vertical (y-axis) positions and velocities
Applying the matrix
Attitude reference system ~
Kalman Filter: Sensor Fusion & Inertial Navigation Beyond "noise removal" and "state estimation," the Kalman filter's most powerful feature is Sensor Fusion. This algorithm brilliantly combines data from multiple cheap, flawed sensors to achieve the precision of a single, high-end sensor.
- Aerospace Roots: Debuting as a star in the Apollo lunar program, the Kalman filter is now the absolute backbone of modern navigation systems for aircraft and satellites.
- Practical Example: We will tackle a fundamental navigation problem: estimating the horizontal attitude (orientation) of an object using data from both accelerometers and gyroscopes.
(Note: These devices are known as inertial sensors, and using them for tracking is called Inertial Navigation. While it encompasses position, velocity, and attitude, we will strictly focus on attitude estimation for simplicity.)
Here, our interest is limited to the horizontal attitude so the roll and pitch angles (
Rate of change in the Euler angles
Current attitude could be obtained by applying the angular velocities measured from the gyros
In the accelerations measured by the accelerometers (
where
Now let us look into detail one by one. The accelerations (
- First, let us consider the case where the system is stationary. In this case,both velocities and accelerations along each axis in body frame are all 0 .
- For the case when the system is moving with constant velocity, the accelerations along each axis in body frame is 0 and since there is no change in the attitude, the angular velocities are also 0 .
- For both cases, the first two terms in the right hand side of Equation become 0 . Then, the equation becomes as simple as following.
From this expression, the formulae for roll and pitch angles could be derived.
The Golden Rule of Sensor Fusion: Complementarity Using a cheap gyro or accelerometer independently is flawed, but their characteristics are perfectly complementary:
- Accelerometer: Its error is bounded and doesn't grow over time (ideal for mid-to-long-term reference), but it's highly noisy in the short term.
- Gyroscope: Highly sensitive to quick changes (excellent for short-term tracking), but suffers from unbounded error accumulation (drift) over time.
The Core Idea: Use the accelerometer's long-term stability to fix the gyroscope's long-term drift! This is the essence of Sensor Fusion: strategically combining sensors to achieve performance impossible by any single unit alone.
Extended Kalman Filter (EKF)
- Most realistic robotic problems involve nonlinear functions:
- Versus linear setting:
- Dynamics model: for
"close to" we have:
- Measurement model: for
"close to" we have:
In a linearized Kalman filter, this problem was solved by linearization. Likewise, an extended Kalman filter derives a linear model by linearizing the nonlinear model. The technique for linearization is classic.
First extended Kalman fiter uses nonlinear system model equations
An EKF example
The system state variables are defined as following.
Since the velocity and the altitude are assumed to be constant, the equation of motion of the system could be described as following:
The meaning of this particular system model is simple. The first formula represents the relationship between horizontal distance and velocity. As you know, it means the rate of change in horizontal distance equals velocity:
The second and third formulae describe the assumption that both the velocity and the altitude are constant. In an ideal system, the rate of change (which is derivative) should be 0, but in real world the value has a slight variation due to various error sources.This is mathematically modeled as the system noise
Now let us look into the measurement model. The physical quantity measured by the radar is slant range.From the figure presented just before, we could see the slant range is defined as following.
On the other hand, the measurement model is nonlinear, so the matrix
All we need to express the tilted angle of a horizontal plane are the roll and pitch angles (
The system model is the one already introduced as Equation:
To implement an extended Kalman filter, the Jacobian of Equation must be known. This is defined as following:
Let us look into the result.
- Convergence: Despite initial errors or noise, the EKF estimations successfully converge to the true values over time.
- Tracking Performance: The algorithm effectively filters out the nonlinear radar measurement noise to track the constant velocity and linear distance.
Unscented Kalman Filter (UKF)
- Problem: The Extended Kalman Filter (EKF) handles nonlinear models by linearizing them using Jacobian matrices (first-order Taylor expansion).
- Limitation: For highly nonlinear systems, this linear approximation introduces significant truncation errors, which can lead to poor tracking performance or even filter divergence.
- Solution: The Unscented Kalman Filter (UKF) was designed to overcome this exact flaw by eliminating the need for explicit linearization.
"It is easier to approximate a probability distribution than it is to approximate an arbitrary nonlinear function."
Instead of trying to linearize the complex nonlinear equation
Picks a minimal set of sample points that match 1st, 2nd and 3rd moments of a Gaussian:
: mean; : covariance; : -th column; : extra degree of freedom to fine-tune the higher order moments of the approximation; when is Gaussian, is a suggested heuristic - EKF approximates
to first order and ignores higher-order terms - UKF uses
exactly, but approximates .
Simple Steps:
- Dynamics update: Can simply use unscented transform and estimate the mean and variance at the next time from the sample points
- Observation update: Use sigma-points from unscented transform to compute the covariance matrix between
and . Then can do the standard update.
UKF summary:
- Highly efficient: Same complexity as EKF, with a constant factor slower in typical practical applications
- Better linearization than EKF: Accurate in first two terms of Taylor expansion (EKF only first term) + capturing more aspects of the higher order terms
- Derivative-free: No Jacobians needed
- Still not optimal!
Quiz
Tutorial Q1
Multi-Sensor Fusion for a Ground Vehicle A ground vehicle moves in a plane and is equipped with three sensors:
- IMU: provides high-frequency measurements of acceleration and angular velocity
- Wheel odometer: provides medium-frequency measurements of forward velocity
- GPS: provides low-frequency measurements of position
The IMU has the highest update rate but suffers from drift.
The wheel odometer is accurate in the short term.
The GPS updates slowly but provides globally referenced position information. A filter needs to be designed to fuse these sensors for vehicle state estimation.
Questions:
1. Using an Extended Kalman Filter (EKF), how should the state variables be selected? Write the state equation and measurement equations, and derive the state matrix. (IMU bias does not need to be considered.)
(1) State Variable Selection
We can choose:
Where
State Equation:
The IMU measures the longitudinal acceleration
Written in vector form:
Where:
The nonlinear state function is:
Because the state equation is nonlinear, the EKF requires computing the Jacobian matrix of
Which yields:
For the measurement equation, this system has two types of external measurements: wheel odometry and GPS. The IMU primarily acts as an input for state prediction here.
The wheel odometer measures the forward velocity of the vehicle, therefore:
Written in matrix form:
The corresponding measurement matrix is:
Written in matrix form:
So the measurement function for the GPS is:
The corresponding measurement matrix is:
2. Why cannot the measurements from the three sensors simply be averaged?
(2) Why can't we just average them directly?
Because the three sensors measure different physical quantities, and they have different precisions, frequencies, and error characteristics. Simple averaging lacks physical meaning and fails to reflect the difference in reliability among the sensors. The purpose of the filter is to rationally weight and fuse this information based on the dynamic model and noise levels.
3. How should the filter be designed to handle different sampling rates?
(3) How to handle different sampling frequencies?
A "high-frequency prediction, low-frequency update" approach is typically adopted: the state prediction is continuously performed using the IMU frequency as the main loop; when wheel odometer data arrives, a single update is performed using the odometer; when GPS data arrives, another update is performed using the GPS. In other words, updates are applied asynchronously as soon as sensor data arrives, without requiring them to be perfectly synchronized.
Tutorial Q2
You are designing an altitude tracking algorithm for an unmanned helicopter executing a hovering mission. To measure the vertical distance to the ground in real-time, a sonar sensor is installed at the bottom of the helicopter. A certain 1D discrete system satisfies
and the process noise variance is
Please calculate sequentially:
(1) Prediction (A priori estimate)
Because the system is 1D (meaning state transition
(2)
(3)
(4)
(5)
Tutorial Q3
For a one-dimensional system, suppose that at time
Two sensors measure the same state simultaneously: Sensor 1 yields
1. The state estimate and covariance after the first update.
2. The final estimate and covariance after the second update.
First update: using Sensor 1 The initial prior prediction is:
The state estimate after the first update is:
The covariance after the first update is:
Second update: using Sensor 2 Now, treat the result of the first update as the new prior prediction for the second update: meaning
The state estimate after the second update (the final estimate) is:
The final covariance is: