MINCO: Geometrically Constrained Trajectory Optimization for Multicopters
Source: [1] Z. Wang, X. Zhou, C. Xu, and F. Gao, "Geometrically constrained trajectory optimization for multicopters", IEEE Trans. Robot., vol. 38, no. 5, pp. 3259–3278, Oct. 2022, doi: 10.1109/TRO.2022.3160022.
1 Preliminaries
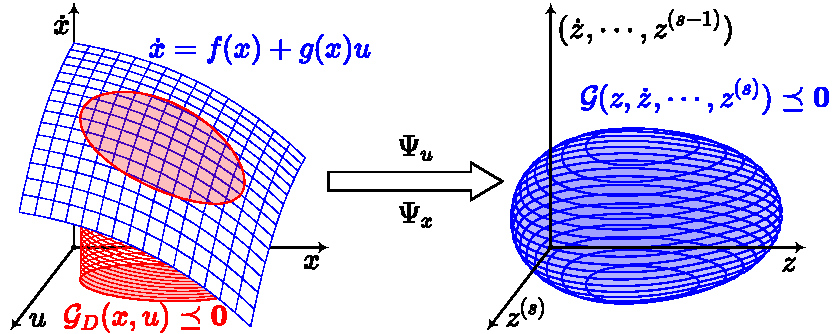
1.1 Differential Flatness
Consider a dynamical system of the following type
with
where
Leveraging the flatness of a system, the trajectory generation is convenient when there are only differential constraints in
the input
where
For dynamics with a small
1.2 Direct Optimization in Flat-Output Space
Fortunately, the differential flatness of multicopters has been well studied and shown to have physically meaningful flat-output space which overlaps with the configuration space. Explicit forms of
where
To generate feasible motions for a multicopter, we first optimize the trajectory
For motion smoothness, the quadratic control effort with time regularization is adopted as a cost functional of
where
Exploiting
Apparently, via the flatness, a constraint on
where
It is worth noting that we do not make further assumptions on the multicopter dynamics and flatness maps. In other words, the proposed framework supports a wide range of multicopters.
1.3 Problem Formulation
Concluding above descriptions gives the following problem:
where
The trajectory optimization
where
As for nonlinear constraints
For simplicity, locally sequential connection is assumed on these convex sets:
where
or, more generally, a bounded convex polytope described by its
For the optimization in
2 Multi-Stage Control Effort Minimization
In this section, we analyze the multi-stage control effort minimization without functional constraints.
For this problem, we propose easy-to-use optimality conditions for general cases, which are proved to be necessary and sufficient. Leveraging our conditions, the optimal trajectory is directly constructed in linear complexity of time and space, without evaluating the cost functional explicitly or implicitly.
Base on them, a novel trajectory class along with linear-complexity spatial-temporal deformation is designed to meet user-defined objectives in various trajectory planning scenarios.
2.1 Unconstrained Control Effort Minimization
When constraint
We solve Linear Quadratic Minimum-Time (LQMT) problems to generate trajectories from spatial-temporal parameters. Although the LQMT problems have extensive studies and applications, only single-stage problems are considered in the literature. We study the multi-stage problems where intermediate points and time vector are fixed in advance for multi-piece trajectories. Consider an
The time interval
Existing works focus on the necessary conditions for special cases of
In control area, a special case where
2.2 Optimality Conditions
We propose necessary and sufficient optimality conditions for
We transform
The augmented system
where
We design a running process for the augmented system in
Denote by
At each timestamp
thus switching the partial state from
The
The conditions in
In this process, the cost functional in
We utilize the Hybrid Maximum Principle to derive necessary conditions for the optimal solution.
Theorem 1: Hybrid Maximum Principle
Let
On the time interval
where
Denote an optimal process for
and a Lagrange function
- Nontriviality condition:
- Adjoint equations: for almost all
,
- Transversality conditions:
- Maximality conditions: for all
,
Proof:
The proof can be directly adapted from Theorem 4 by Dmitruk and Kaganovich. Here we only consider each system
According to Theorem 1, the costate
where
By applying the adjoint equation
By applying the adjoint equation for
which is expanded as
It is obvious that
According to maximality conditions
i.e.,
Then,
To further explore structures of the solution, we generate the Lagrange function using the cost of augmented system along with all constraints in
where
Because
Finally, by substituting
We finally know that the optimal control of the problem
Now we conclude the conditions derived from both
Theorem 2: Optimality Conditions
A trajectory, denoted by
- The map
is parameterized as a degree polynomial for any ; - The boundary conditions in
; - The intermediate conditions in
; is times continuously differentiable at for any where .
Moreover, a unique trajectory exists for these conditions.
Proof (Sketch):
Details of Proof (Sketch)
The proof of necessity is evident in the analyses from
- The first and fourth conditions always determine a linear spline space of dimension
for any sequence of ; - The second and third conditions are shown to form a square coefficient matrix on a basis of the spline space;
- The matrix is proved to be nonsingular since
for each , implying the existence and uniqueness of solution; - The existence and uniqueness for the necessary conditions yield their sufficiency. This proof of sufficiency is detailed in Appendix of Paper (TODO).
To further explain the optimality conditions, we take the multi-stage jerk minimization as an example.
In this example, the position, velocity and acceleration are states of the jerk-controlled system (
The continuity of state only requires the continuity up to acceleration of the minimum-jerk trajectory, while jerk and snap of the optimal trajectory are also continuous everywhere. Accordingly, if we enforce all these continuity conditions, then Theorem 2 guarantees that only one trajectory exists, which is exactly the optimal one.
2.3 Minimization Without Cost Functional
Theorem 2 provides a direct way to construct the unique optimal trajectory. The computation enjoys linear complexity in time and space. It does not even require explicit or implicit evaluation of the cost functional or its gradient.
Consider an
where
where
To compute the unique solution for
Especially, define
The linear system for the optimal coefficient matrix is
where
It is essential that the uniqueness in Theorem 2 ensures the nonsingularity of
As for a nonsingular banded system, its Banded PLU Factorization always exists, which can be employed to compute the solution with
2.4 MINCO Trajectories With Spatial-Temporal Deformation
For multicopters, there are often task-specific requirements apart from feasibility, such as the perception quality in active SLAM or the occlusion rate in aerial videography. These user-defined requirements majorly need to flexibly and adaptively deform both the spatial and temporal profile of a trajectory. Therefore, we select the intermediate points and the time vector as two salient parameters in
We denote the intermediate points by MINCO hereafter. The MINCO trajectory class, denoted by
The dimension
Intuitively, all trajectories in
We denote any user-defined objective (or constraint) on a trajectory by a
To accomplish deformation of
Obviously, evaluating
Now we give a linear-complexity scheme to compute
Without causing ambiguity, we omit parameters in
As for the gradient w.r.t.
Then,
where
The definition of
where
We only need to compute
where the inverse is only done for a diagonal matrix and
such that
where
As for the gradient w.r.t.
Thus,
The banded structure of
Then we obtain the gradient w.r.t.
where
Finally, we finish the computation of
3. Geometrically Constrained Flight Trajectory Optimization
In this section, we provide a unified framework for flight trajectory optimization with different time regularization
The spatial-temporal deformation is utilized to meet various feasibility requirements. Lightweight schemes are specially designed to eliminate geometrical constraints such that the trajectory can be freely deformed. For continuous-time constraints, a time integral penalty functional is proposed to ensure the feasibility without sacrificing the scalability.
Finally, our framework transforms the constrained trajectory optimization into a sparse unconstrained one which can be reliably solved.
3.1 Temporal Constraint Elimination
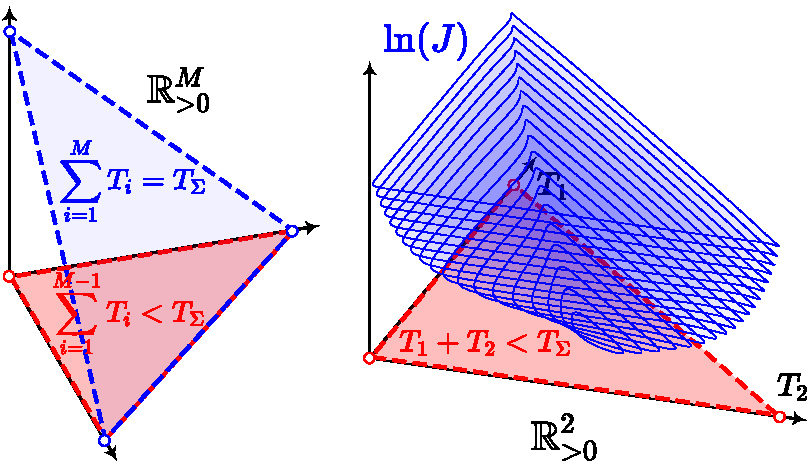
Deforming MINCO needs standard optimizers that are often designed for Euclidean spaces. However, the trajectory definition and cost functional~
For polynomial splines, the control effort in
where
It is natural to optimize
We use diffeomorphisms to eliminate constraints for
It is clear that
Proposition 1:
By exploiting the explicit diffeomorphism
Optimizing
Differentiating the layer in
where
For either
Thus, the only concern is whether
Proposition 2
Denote by
if and only if ; is positive-definite (or positive-semidefinite) at , if and only if is positive-definite (or positive-semidefinite) at .
Proof: See Appendix in the original paper.
Proposition 2 confirms that
3.2 Spherical Spatial Constraint Elimination
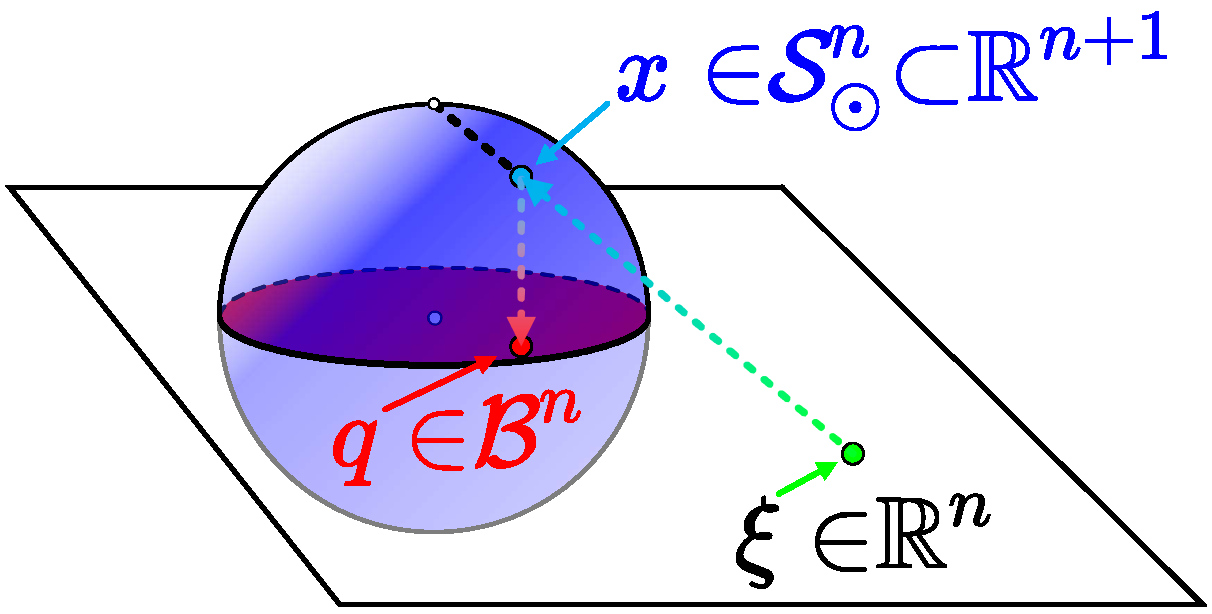
We enforce motion safety by confining trajectories into the feasible region MINCO, the traverse time for every primitive can be directly optimized. Thus, we fix the piece assignment before optimization, rather than resorting to integer variables during optimization. Consequently, intermediate points should be contained by the overlap between primitives, forming inequalities. For Inequality Constrained Problems (ICPs), general methods successively approximate the constraints via additional parameters. However, we aim to apply the constraints directly and efficiently. Therefore, we propose spatial constraint elimination to enforce them exactly, leveraging their geometrical properties.
Consider the constraint
We utilize a smooth surjection to map
The inverse stereographic projection
Note that
The map is described by
which is indeed a smooth surjection onto
The map
Accordingly, denote by
Denote by
If the optimization needs to start from an initial guess
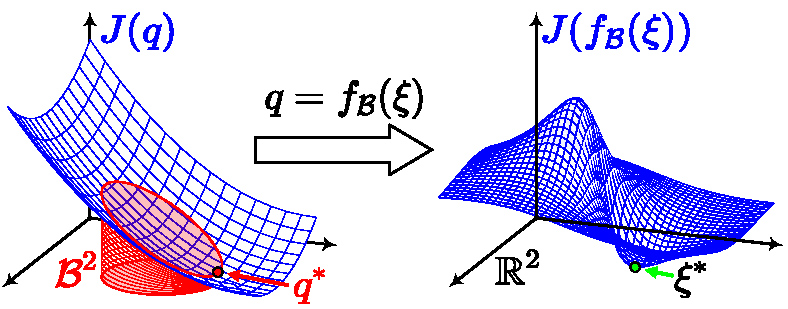
Similarly, we analyze influences that the smooth surjection
3.3 Polyhedral Spatial Constraint Elimination
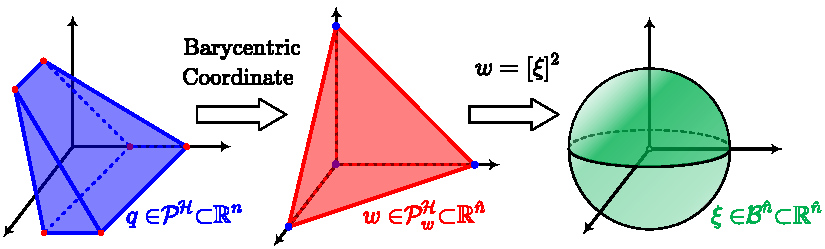
Now we consider the elimination of polyhedral constraints. Specifically,
where
To achieve this, we use the
The procedure to eliminate a polytope constraint is illustrated in the Fig. 5. We denote all
where
The Main Theorem of Polytope Theory confirms the equivalence between
This process does not produce additional nonlinearity in the optimization problem except that the dimension of decision variables is increased. Therefore, we only consider the decision variables on
The simplex
Consequently, we can utilize the smooth surjection
A new coordinate
If an initial guess
The map
Direct constraints on
3.4 Time Integral Penalty Functional
After eliminating direct constraints,
For a trajectory
where
Secondly, penalty methods have no requirement on a feasible initial guess which is nontrivial to construct.
We define the time integral penalty functional for
where
Practically,
where
where
3.5 Trajectory Optimization via Unconstrained NLP
Due to
where
To generate trajectories for a flat multicopter, we first parameterize its flat-output trajectory as
User-defined
Apparently, the gradient propagation is derived for all layers except
4 Conclusion (By GPT-5.2 in Github Copilot)
MINCO can be viewed as a back-end trajectory generator + lightweight unconstrained optimizer: given a piece assignment and boundary/intermediate conditions, it constructs the unique minimum-control-effort spline (solving a multi-stage LQMT like
Below is a practical procedure you can follow to implement the MINCO pipeline.
MINCO procedure (implementation-oriented)
Inputs
- Flatness order
(e.g., jerk or snap ), weights , and time regularization in , , . - Start/goal boundary derivatives
(see ). - Free-space approximation
(see – ), plus piece assignment (e.g., pieces per primitive). - Continuous-time dynamic constraints
(obtained from via flatness maps, see – ).
Decision variables
- Spatial variables
that generate intermediate points using a smooth surjection (e.g., ball case , polytope case via ). - Time variables
that generate via a diffeomorphism (e.g., fixed-sum case ; gradient uses ).
Algorithm
Discretize the topology (piece assignment)
Parameterize the flat-output trajectory as a MINCO spline
Eliminate direct constraints by variable transformations
Handle continuous-time constraints via integral penalty
Solve the unconstrained NLP
- Minimize the relaxed objective
- Use L-BFGS (as described at the end of §3.5). For gradients, propagate through layers:
- Minimize the relaxed objective
Recover the feasible multicopter trajectory
This procedure is exactly the “MINCO-as-a-module” viewpoint: (i) construct the unique minimum-effort spline from