Multi-Agent Planning
Source:
[1] L. Quan et al., ‘Robust and efficient trajectory planning for formation flight in dense environments’, IEEE Trans. Robot., vol. 39, no. 6, pp. 4785–4804, Dec. 2023, doi: 10.1109/TRO.2023.3301295.
[2] L. Quan, L. Yin, C. Xu, and F. Gao, “Distributed swarm trajectory optimization for formation flight in dense environments,” in Proc. Int. Conf. Robot. Autom., 2022, pp. 4979–4985.
[3] Z. Wang, X. Zhou, C. Xu, and F. Gao, "Geometrically constrained trajectory optimization for multicopters", IEEE Trans. Robot., vol. 38, no. 5, pp. 3259–3278, Oct. 2022, doi: 10.1109/TRO.2022.3160022.
[4] Teo K L, Rehbock V, Jennings L S. "A new computational algorithm for functional inequality constrained optimization problems"[J]. Automatica, 1993, 29(3): 789-792.
Notation
1 Adaptive description of swarm formation (Sec. IV in [1])
1.1 Graph-based Formation Definition
In this article, a swarm formation of
In our work, each robot can obtain the positions of all robots
where the non-negative edge weight
With the above matrices, the symmetric normalized Laplacian matrix of graph
where
(Explained by ChatGPT 5.5) The distance measurement is invariant to translation and rotation. For uniform scaling:
A more precise statement is that
is a shape descriptor invariant under similarity transformations (rotation + translation + uniform scaling). Since distances are also unchanged by reflection, it is actually invariant under the full Euclidean similarity group, including mirror reflections. Other properties:
- Symmetric and positive semidefinite
- Eigenvalues lie in a bounded interval:
- The multiplicity of the zero eigenvalue corresponds to the number of connected components in the graph. Since the grph is complete:
- The largest eigenvalue
is related to the maximum degree of the graph and can indicate the presence of highly connected nodes (hubs) - Known eigenvector for
is the constant vector , which reflects the uniform distribution of vertices in the graph - The second smallest eigenvalue (normalized algebraic connectivity) indicates how well connected the graph is: larger values suggest stronger connectivity and robustness to node removal, while smaller values indicate a more fragile structure
- The eigenvalues and eigenvectors of
can be used for spectral clustering, community detection, and dimensionality reduction in graph-based machine learning tasks - The eigenvectors (Laplacian eigenmaps) can be used for clustering and dimensionality reduction
- Spectral invariance: the spectrum of
is a compact shape descriptor. Many formation-recognition methods use only the eigenvalues because eigenvalues are independent of robot numbering up to permutation. - Invariance to robot relabeling (permutation):
is invariant under any permutation of the robot indices, which means that the formation similarity metric based on does not depend on how we label the robots. - The trace of
is equal to the number of vertices (since the diagonal entries are all 1) - The Frobenius norm
is related to the total edge weight and can be used as a measure of graph connectivity - The normalized Laplacian can be interpreted as a discrete analog of the continuous Laplace-Beltrami operator on a manifold, which is useful for analyzing the geometry of the formation
- The normalized Laplacian can be used to define a diffusion process on the graph, which can model how information or influence spreads through the swarm formation
- the spectrum alone does not always uniquely determine the formation. Different formations can occasionally be cospectral. However, in practice, the spectrum of
is often sufficient to distinguish between different formation shapes, especially when combined with other features or constraints. - The normalized Laplacian is particularly useful for comparing formations of different sizes, as it normalizes the influence of the number of robots and their connectivity, allowing for a more meaningful comparison of formation shapes.
Finally, we use graph theory to describe various desired formation shapes, such as squares, hexagons, and pyramids.
By specifying the desired positions
It's important to note that the desired formation shape is independent of the coordinate system as long as the relative positions are provided.
1.2 Differentiable Formation Similarity Error Metric
To assess the deviation from the desired formation, we propose a differentiable formation similarity error metric as
where
As a graph representation matrix,
In particular, under the distributed framework, each robot can only change its positions to reduce the overall formation similarity error. Therefore, the only variable for robot
Our metric is analytically differentiable with respect to the position of each robot. For robot
According to our metric
Then the gradient
As for
1.3 Optimal Formation Position Sequence
TODO: Previous work Previous work [2] incorporated
Considering the simplified equation for coupled trajectory optimization
where
The primary purpose of calculating
Consequently, the coupled trajectory optimization
To address this issue, we must identify an equivalent approach with reduced computational complexity to replace the function of
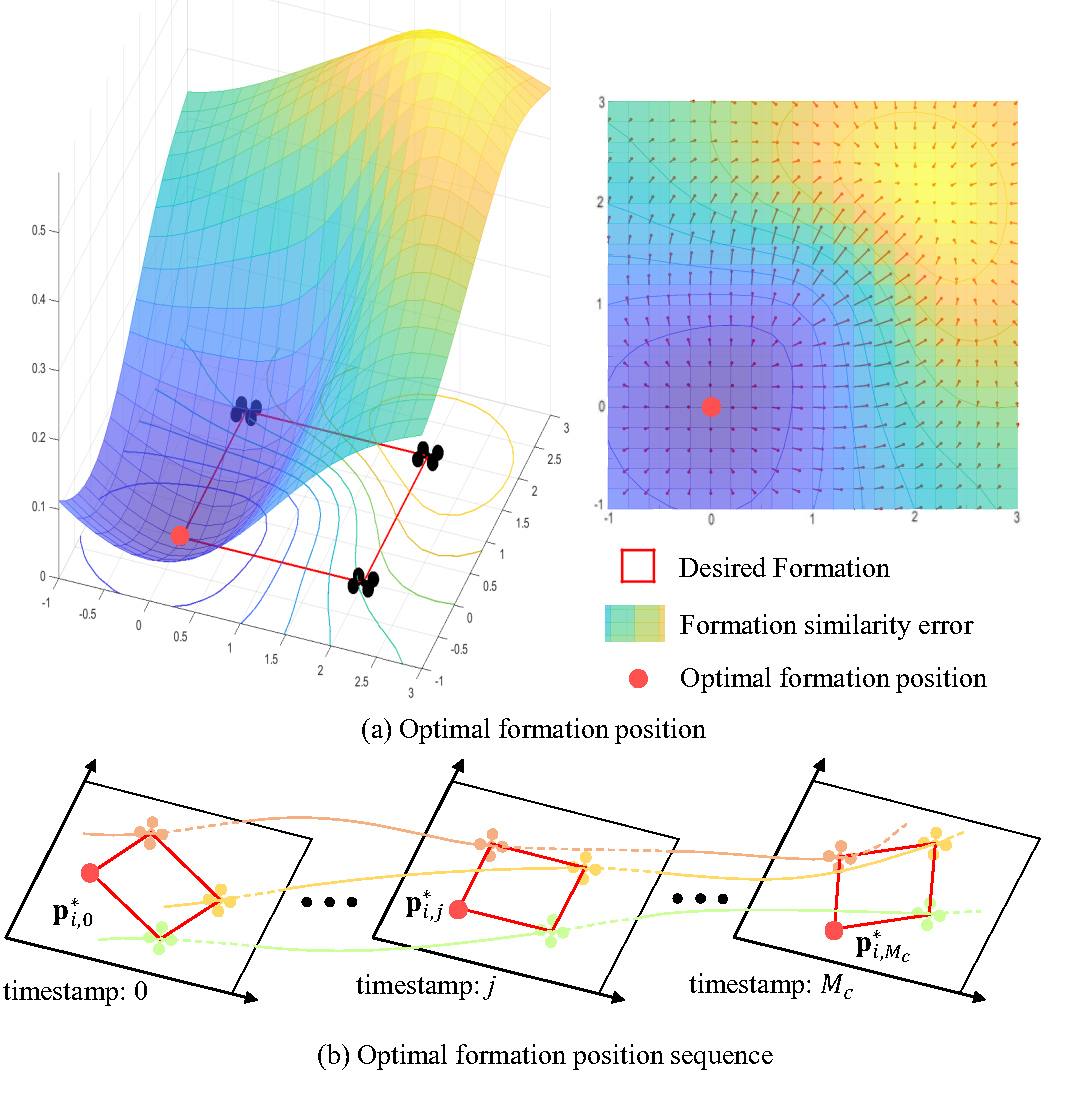
It is evident from the figure that there exists an optimal formation position
In the future period with a sequence of timestamps
Since the optimal solutions of
Thus, we can effectively solve the coupled trajectory optimization with a two-step procedure
As a result, the previously required calculation of
Formula
In engineering practice, since graphs
To ensure a smoother trajectory, we introduce the uniform optimal formation position sequence
where
We use the quasi-Newton method to solve this unconstrained optimization problem
By doing so, the trajectory resulting from these discretized points in the next section can be smoother and avoid sudden spatial changes.
2 Spatial-temporal trajectory optimization for formation flight
2.1 Trajectory Representation
The differential flatness of multicopters benefits trajectory generation without integrating differential equations. Moreover, the motion planning of multicopters can be performed on low-dimensional smooth trajectories.
Here we adopt a state-of-the-art trajectory representation named MINCO to achieve minimum control effort spatial-temporal trajectory planning for swarm aerial robots in three-dimensional environments. MINCO conducts spatial-temporal deformation of the flat-output
where
A
where
For an
Furthermore, MINCO is advanced in convert
2.2 Problem Formulation
After determining the desired formation shape in the last section, we expect a cluster of trajectories for swarm robots, which are smooth, collision-free, and formation maintained.
In practice, navigating swarm robots in an unknown dense environment with FOV-limited sensors and onboard computer requires an efficient real-time planner focusing on local information. Besides, centralized optimization is limited by the scale of the swarm.
Therefore, we choose a distributed local trajectory optimization for formation flight as follows
We define costs
2.3 Constraints Transcription
To solve the continuous constrained optimization problem
Penalty function method in [4] (Concluded by ChatGPT 5.5) A functional inequality constrained optimization problem has the form
where
is the cost function, is the constraint function, and is a continuous variable. The penalty function method transforms this problem into an unconstrained optimization problem by introducing a penalty term that penalizes any violation of the constraints. The transformed problem can be expressed as where
is a penalty parameter that controls the weight of the penalty term. The key observation is that is zero when the constraint is satisfied (i.e., ) and positive when the constraint is violated (i.e., ).
Finally, the continuous constrained optimization problem is converted to a discrete unconstrained optimization problem
where
- (
) swarm formation similarity; - (
) denote control effort; - (
) total time; - (
) obstacle avoidance; - (
) swarm reciprocal avoidance; - (
) dynamic feasibility.
In the previous work[2], we used the fixed number sampling points
However, considering that the total time
Therefore, we take fixed-time-interval sampling points for the whole trajectory to ensure the accuracy of the penalty function sampling transformation
where
For the trajectory planning of swarm robots, the fixed time interval sampling points
Therefore, it is feasible to calculate the states of other robots w.r.t
Then we can solve the uniform formation position sequence optimization
Despite the optimization problem is not differentiable when sampling number
2.4 Cost Functions and Gradients
Given the fixed sampling time interval
The cost of various general purpose penalties at
then the cost function
where
And MINCO allows any second-order continuous cost function
In
where the calculation of
- Cost of Swarm Formation Similarity
In Sec. 1.3, we decouple the formation similarity error metric from trajectory optimization by constructing an unconstrained optimization problem to calculate the uniform optimal formation position sequence for each sampling point. This improvement avoids multiple calculations of formation similarity metric . Then, we use the quadratic form to calculate the cost of swarm formation similarity
- Control Effort
The ( here) control input for the trajectory and its gradients are written as
Total Time
In order to ensure the aggressiveness of the trajectory, we minimize the total time . The gradients are given by and . Cost of Obstacle Avoidance
Obstacle avoidance penalty is computed using Euclidean Signed Distance Field (ESDF). We penalize the sampling points which are too close to the obstacles
where
where the
- Cost of Swarm Reciprocal Avoidance
We penalize when it is too close to the trajectories at the fixed timestamp , where represents the all other robots in the swarm. Compared to previous work[2], the state of other robots with fixed timestamp are constant during the optimization process and do not produce a gradient w.r.t for the cost function . So the optimization problem and the gradients are simplified. The cost of swarm reciprocal avoidance is defined as
where
- Cost of Dynamic feasibility
We limit the maximum value of velocity and acceleration to guarantee that the robots can execute the trajectory.
where
2.5 Discussion on solution quality of trajectory optimization
The proposed trajectory optimization process
To address concerns regarding local minima and infeasible solutions, we have implemented measures that prioritize safety and dynamic feasibility while maintaining high-performance formation flight.
- Firstly, we utilize hybrid-A searching algorithm* to generate initial trajectories that are collision-free and dynamically feasible, ensuring a valid final solution trajectory.
- During optimization, we give greater weight to obstacle avoidance and dynamic constraints to prioritize safety and feasibility.
- Additionally, we conduct collision checks on trajectories to enhance safety.
- Moreover, our distributed swarm optimization framework effectively mitigates the impact of local minima on overall formation performance.
Implementing these measures, our method reliably achieves robust formation flight while maintaining computational efficiency.
9 Conclusion
Procedure (two-step decoupled formation trajectory optimization)
Inputs:
- Desired formation (relative positions)
; - Initial/terminal states
; - Obstacle ESDF
; - Safety clearances
; - Dynamic limits
; - Weights
; - Sampling interval
.
- Describe the desired formation with a graph.
- Build the (complete) formation graph
, compute , , and normalized Laplacian via – . - From
compute (codes).
bool SwarmGraph::setDesiredForm()- Define formation similarity and its gradients.
- Use the differentiable similarity metric
in and its gradients – to measure formation-shape error (codes).
bool PolyTrajOptimizer::swarmGraphGradCostP()- Precompute the (uniform) optimal formation position sequence.
- For each robot
and each discrete timestamp , solve the formation-only optimization to obtain the optimal formation positions (Sec. 1.3). - Replace the
formation similarity term by a quadratic distance surrogate , yielding the decoupled two-step pipeline . - Add the uniformity regularizer and solve
– to obtain the uniform sequence .
- Initialize a feasible trajectory for each robot.
- Generate an initial collision-free, dynamically feasible trajectory (e.g., hybrid-A*) to warm start the optimizer (Sec. 2.5). Codes: computeInitReferenceState
astarWithMinTraj astarSearchAndGetSimplePath AstarSearch
- Parameterize each trajectory using MINCO.
- Represent the piecewise polynomial trajectory with variables
using – : (Codes: Variables & Grad in costFunctionCallback). - Formulate the distributed local optimization objective and constraints as
.
- Transcribe continuous constraints with fixed-interval sampling.
- Sample the full trajectory using the fixed time interval
to obtain as in , so timestamps remain constant while changes. - For reciprocal avoidance, query other robots’ broadcast trajectories at the fixed timestamps
.
- Assemble the discrete unconstrained optimization objective.
- Convert
into the sampled objective using trapezoidal integration . - Use the following penalty/cost terms at samples:
- Optimize per robot with quasi-Newton and analytic gradients.
- Compute gradients w.r.t. coefficients and durations using the MINCO mapping and chain rules
– . - Solve
with a quasi-Newton method until convergence; run collision checks and keep high weights on obstacle/dynamic penalties for safety (Sec. 2.5).
- Execute and iterate.
- Broadcast the optimized trajectory to neighbors and execute; repeat the above steps in a distributed replanning loop as new environment/neighbor information arrives.