Formation Control
1 Introduction [1]
Consider a system of
Let the desired formation for the agents be represented by an infinitesimally and minimally rigid framework
In practice, the geometric shape/structure of the desired formation is dictated by the mission to be accomplished by the agents. When translating the desired shape into a framework, one needs to include enough edges to ensure that
The actual formation of the agents is represented by the framework
indicates the minimum number of inter-agent distances that need to be controlled for the desired formation to be successfully reached. indicates the agent pairs that can sense and/or communicate with each other.
We make the following assumptions regarding the desired and actual formations:
Assumption 1
The set where the agents achieve the desired formation is nonempty, i.e., there exist
Assumption 2
The formation and sensor graphs are the same, i.e.,
Connectivity maintenance prevents the occurrence of flex ambiguities since temporary loss of edges cannot happen.
Assumption 3
At
Assumption 4
The only position information being measured is the relative position of agent pairs in
We will deal with three types of control problems:
- Formation Acquisition
- Formation Maneuvering
- Target Interception
Problem 1: Formation Acquisition
The goal is for the agents to acquire and maintain a pre-defined geometric shape in space. The control objective for formation acquisition, which serves as the common, primary objective for the other two problems, can be mathematically described as to design
which is equivalent to
Since only the inter-agent distances are to be directly controlled, the actual formation can converge to any isometry of
Problem 2: Formation Maneuvering
The agents are required to simultaneously acquire a formation (i.e., satisfy
where
In practice, the selection of
When
. , i.e., there is an edge between each follower and the leader.
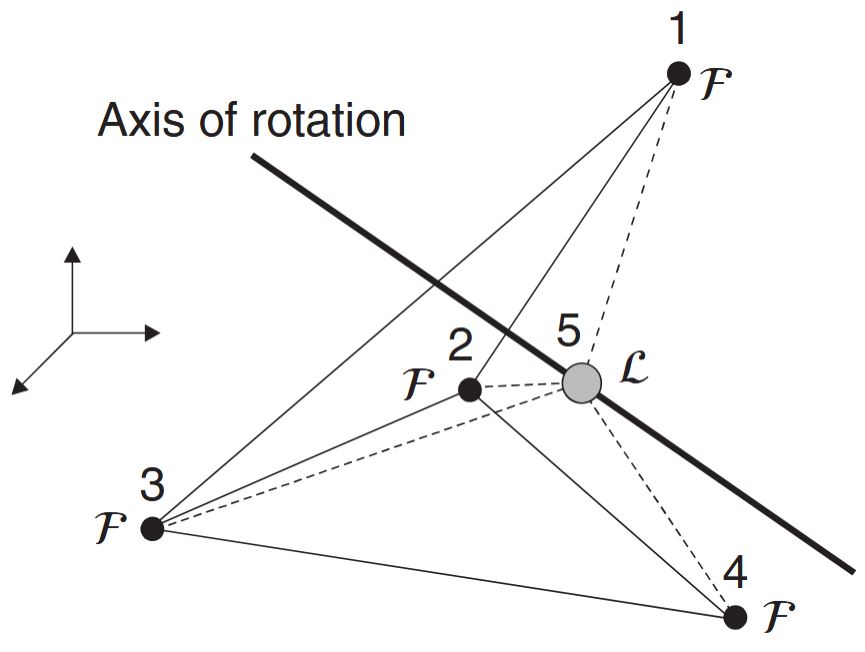
An example of
The association of a leader agent (instead of a virtual leader) with the axis of rotation is done for convenience (not necessity) since the leader’s relative position to the followers can be measured and it will not have to undergo any rotation. Note that if one uses a virtual leader, its location would have to be known in order to calculate its position relative to the agents (see
Problem 3: Target Interception
The agents should intercept and surround a (possibly evading) moving target with a pre-defined formation. Here, we will also use the leader–follower approach by taking the
- Selecting
such that (Unlike formation maneuvering with rotation, we do not need the second condition for target interception) - The leader chasing the target
- The followers tracking the leader while maintaining the desired formation. Thus, if
denotes the target position, the secondary objective for this problem is that approach as time evolves, which (with abuse of notation) we express as
Before beginning with the control design, some theorem and corollary statements will be made without proof.
Theorem 1.1 (Originally from [1] of Theorem C. 1)
Consider the SISO LTI system
where
- If
, then is continuous, and as . - If
, then , and is uniformly continuous. If, in addition, as , then as .
Theorem 1.2 (Originally from [1] of Theorem C.2)
Let
for all
Corollary 1.1 (Originally from [1] of Corollary C.1)
If
Input-to-state stability bridges the gap between the notions of Lyapunov stability and input–output stability by quantifying the effects of both initial conditions and external (control or disturbance) inputs on the system state.
Definition: Input-to-State Stability
A dynamical system
The above inequality has several implications.
- For any bounded input, the state is bounded.
- As
, the state is ultimately bounded by function . - If
as , so does .
Theorem 1.3 (A corollary to Barbalat's Lemma, originally from [1] of Theorem C.3)
Consider the function
Theorem 1.4 (Originally from [1] of Theorem C.4)
Consider that
Theorem 1.5 (Originally from [1] of Theorem C.5)
Consider the interconnected system
If subsystem
Theorem 1.6 (Originally from [1] of Theorem C. 6)
If
and
in
where
represents the "ball" of radius
Then
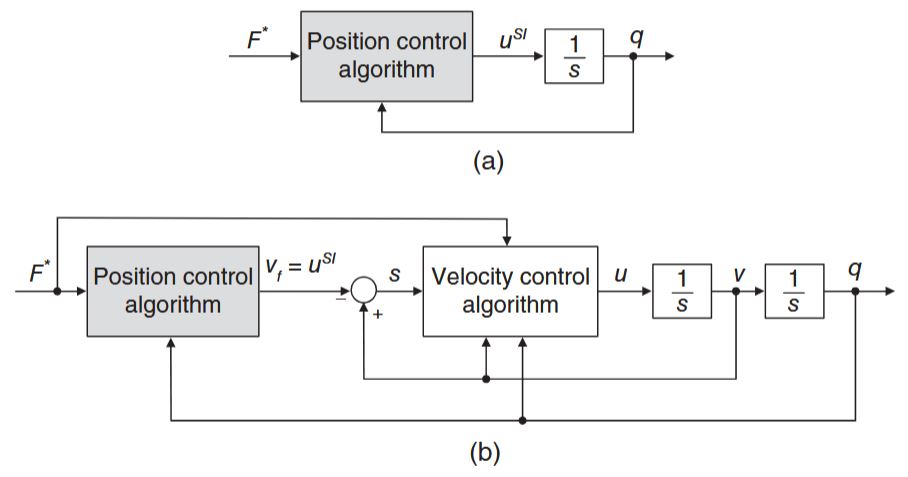
2 Single-Integrator Model [1]
This section will set the foundation for the formation control designs. We use here a very simple model for the motion of the agents known as the single-integrator model, which only includes two variables: position and velocity. This is a simplified kinematic model for omnidirectional robots (e.g., mobile robots with Swedish wheels). Specifically, we consider a system of
where
where
Formation controllers based on
2.1 Formation Acquisition
We begin with the formation acquisition problem defined in Section 1. Given
It is appropriate at this point to elaborate on an issue mentioned at the end of Section of framework ambiguities. The inputs
which is equivalent to
Note that
To simplify the notation in the following derivations, we define the relative position of two agents as
and let
Note that
Let
which can be rewritten as
using
where
Using definition of rigidity matrix
where
Lemma 2.1
For nonnegative constants
Proof:
Details of Proof
First, from the definition of
From
The control law for solving the formation acquisition problem is given in the following theorem. Its structure is based on
Theorem 2.1
Consider the formation
and
where
Proof:
Details of Proof
Given that
Since
where
From the form of
Due to
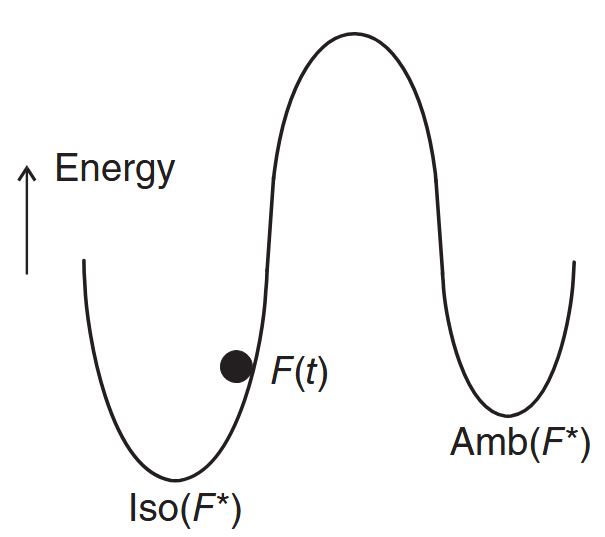
The initial condition
- Remain infinitesimally rigid for all time and
- Be closer to a framework in
at than to one in in order to avoid converging to an ambiguous framework.
The former constraint is satisfied by
The control
which is only a function of
Notice that each individual term of the summation in
The stability result of Theorem 2.1 guarantees that the desired formation is acquired up to rotation and translation. In other words, the formation acquisition controller does not regulate the formation to a pre-defined global location in space. This is a reflection of the facts that
Since we are only concerned with the inter-agent distances, any coordinate frame can be used to implement
where the superscript denotes the coordinate frame in which the vector is specified. From
since
Finally, the control
where
The derivative of
where
which is the same as
2.2 Formation Maneuvering
In this section, we solve the formation maneuvering problem defined in Section 1.4 using model
Theorem 2.2
Consider the formation
where
Proof:
Details of Proof
TODO It follows from (1.20) and
Therefore, the proof of Theorem 2.1 can be directly followed to show that
From
Since we proved that
The control
Another interesting point is that, despite being based on the single-integrator model,
The control law can be written element-wise as
which shows that it is decentralized. Note that in many applications the signals
2.3 Flocking
Here, we consider the special case of formation maneuvering where the desired velocity only includes the translation component. Recall from Section 1 that this is commonly referred to as flocking. Unlike last Section, we consider that the desired flocking velocity is only available to a subset of agents. We will overcome this constraint by employing a distributed observer that estimates this velocity by exploiting the connectedness of the formation graph.
Constant Flocking Velocity
We first consider the case where the flocking velocity is constant. Let
where
Theorem 2.3
Consider the formation
Proof:
Details of Proof
Let
denote the flocking velocity estimation error for agent
As part of this proof, we will show that
After substituting
upon application of Property
Now, we turn our attention to deriving the dynamics of the estimation error. First, notice that
where
where we used the fact that
Finally, due to the asymptotic stability of
The form of
Time-Varying Flocking Velocity
The observer scheme in
where
The dynamics of the estimation error now become
where
where
If we define the Lyapunov function candidate
we get that
where a.e. is the abbreviation for the term "almost everywhere". If we define
By choosing
Now the proof that
2.4 Target Interception with Unknown Target Velocity
We now turn our attention to the target interception problem defined in Section 1. We assume the target motion is such that
To simplify the notation, we let
denote the interception error between the leader and target. The control, which will include a term to "learn" the unknown target velocity, will take the general form
where
Before presenting the control law, a lemma is related to
Lemma 2.2
Let
If
then
where the positive constant
Proof:
Details of Proof
After integrating by parts the second integral on the right-hand side of (2.50) and applying Lemma 1 of [44] to the third integral, we obtain
Using the fact that
Applying
when
Theorem 2.4
Consider the formation
renders
Proof:
Details of Proof
After substituting
Due to Property in the Infinitesimal Rigidity, the second term on the right-hand side of
We now proceed to prove
Differentiating
where
where
whose derivative along
where
[^2]Since
which means that
Finally, we know
Similar to the formation maneuvering control, the target interception controller
ensures formation acquisition guarantees target interception
The controller for the followers can be written element-wise as
for
whereas the control for the leader is given by
Finally, note that the target interception error
2.5 Dynamic Formation Acquisition
So far, we have only considered formation acquisition when the desired formation
Note that dynamic formation acquisition is independent of what we call formation maneuvering. In the former, the time-varying nature is related to the formation itself, whereas in the latter, the formation (whether static or dynamic) maneuvers as a virtual rigid body. The formal statement of the dynamic formation acquisition problem is as follows.
Problem 4 (Dynamic Formation Acquisition)
Let the desired formation be represented by a dynamic, infinitesimally and minimally rigid framework
We assume the desired distances are sufficiently smooth functions of time[7]. The control objective is to design
or equivalently
Because of the time-varying nature of
where
where
with elements ordered as
Theorem 2.5
Consider the formation
where
The proof of this theorem is nearly identical to the proof of Theorem 2.1 so the details are omitted. The main difference is that, since
From this point on, the proof of Theorem 2.1 can be directly followed to show that
A fundamental difference exists in the implementation of (2.71) in comparison to the previous controllers of this chapter. Namely, the matrix
Formation maneuvering can be performed on top of dynamic formation acquisition by modifying
where
Notes
The directionality of the information exchange among agents is an important design factor. This issue is of practical importance since it relates to the number of communication, sensing, and/or control channels of the multi-agent system.
In the case of bidirectional information exchange, a pair of agents concurrently controls the distance between them, whereas only one agent in the pair is responsible for this task in the unidirectional case. In terms of graph theory, bidirectional (resp., unidirectional) formation controllers are based on undirected (resp., directed) graphs. Undirected formation controllers have built-in redundancy, providing robustness. However, it can also lead to instability in the formation acquisition if agent pairs use slightly different values for the distance between them due to measurement errors. It was shown that this measurement mismatch causes a distortion of the formation from its desired shape and a circular (resp., helical) orbit of the distorted formation in 2D (resp., 3D).
One possible remedy for this problem is to have the agents communicate their respective measurements to one another and then use a common value for control (e.g., the average of the two measurements).
Yet another solution is to use a directed graph-based controller since it reduces the overall number of communication/sensing/control channels while avoiding the potential conflict between a pair of agents trying to achieve the same objective. However, in directed graphs it is possible to have cycles in the pathways, which are more challenging to control and can lead to formation instability. Therefore, the issue of cyclic versus acyclic graphs is an important consideration for directed formation control.
3 Double-Integrator Model [1]
In this section, we re-discuss the class of formation controllers presented in Chapter 2 in the context of a slightly more refined model, viz., the double-integrator model. We will follow the same format as the previous section for ease of correlation.
The double-integrator model accounts for the agent acceleration by treating the agent as a point mass. Therefore, it can be considered a very simple dynamic model for omnidirectional robots. Given a system of
where
Note that the system transfer function matrix is now
Double-Integrator Model for Formation Control
As in Section 2.1, we begin by deriving the distance error dynamics. To this end, we use
where
Given that
where
Due to the new error variable
where
After taking the time derivative of
where
3.1 Cross-Edge Energy
Before presenting the formation controllers, we need to discuss a complication in the stability analysis of the closed-loop system that arises from the double-integrator model. Specifically, this complication is related to the avoidance of flip ambiguities.
Recall that for the single-integrator model, the position of the initial formation needs to be restricted to prevent convergence to a flip ambiguity since the velocity-level control input is designed to promote convergence to
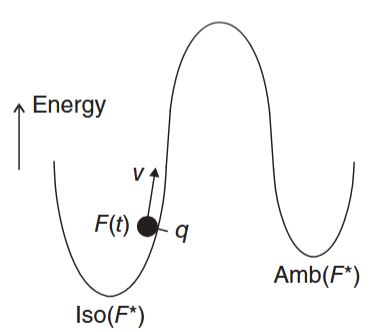
While the need for an upper bound on the initial energy of the formation is evident, its precise value is difficult to calculate in general. For simple formations, one may be able to calculate a conservative value for the energy upper bound as illustrated next. Consider the desired triangular formation in Figure 3.3 along with one of its flipped versions. Note that a flip may occur whenever an agent has enough energy to cross the edge connecting the two other agents, e.g., agent 1 crossing edge
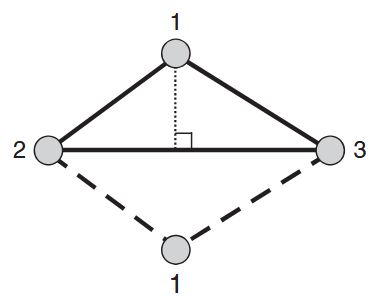
The question is then: What is the minimum energy needed for this to happen? Hereafter, we refer to this minimum energy as the cross-edge energy,
A conservative estimate for the cross-edge energy can be made by using the following observations:
- The cross-edge energy is related to the energy that drives the agents to a collinear formation
- The minimum collinearity energy is given by the agent with the smallest distance to its cross-edge, e.g., the dotted line in Figure 3.3.
These rules facilitate the cross-edge energy estimation because they are only position dependent. Furthermore, we have from
It can be found that the above function reaches a minimum at
Notice that the condition
For formations with
3.2 Formation Acquisition
The formation acquisition controller for
Theorem 3.1
Given the formation
and
where
Proof:
Details of Proof
Following the arguments used in the proof of Theorem 2.1, we have that
for
The expression for
where from
The control
for
This control is decentralized since its implementation only requires each agent to measure its own velocity and the relative position and relative velocity to neighboring agents. The agent's velocity can be measured using onboard sensors such as an odometer and a compass.
3.3 Formation Maneuvering
The formation maneuvering control law for the double-integrator model
where the formation maneuvering velocity
We will not present the formal statement and proof of this result, but only discuss the aspects in which it differs from the proofs of Theorems 2.2 and 3.1. This is namely the proof that
The term
where
3.4 Target Interception with Unknown Target Acceleration
Solving the target interception problem for the double-integrator model requires a more elaborate solution than the one presented in Section 2.4 for the single-integrator model. Here, we consider that the target position
Theorem 3.2
Let the initial conditions be such that
Proof:
Details of Proof
First, notice that the differential equations describing the
where
where
For
where the subscript
where
A few observations are in order concerning the structure of
is not included in as it is in because the derivative of is a function of the unknown signal . Hence, only the measurable terms of appear in . Since cannot be directly cancelled by the control, it is instead dominated by the variable structure term as shown in . - Comparing
and , notice the absence of the term in the latter. Unlike the control in Theorem 2.4, the presence of this term in is not necessary for proving the converge of to zero. If was included , the above stability analysis would still hold with the exception that the auxiliary variable in would become simply .
When expressed element-wise, the control
As one can see, the
3.5 Dynamic Formation Acquisition
When solving the dynamic formation acquisition problem (see Problem 4 in Section 2.5) for the double-integrator model, we require that the time-varying distance
Similar to the formation maneuvering control law of this chapter, the dynamic formation acquisition control input will take the form of
The term
and
The proof of stability uses the same Lyapunov function candidate
for
As in the single-integrator case, formation maneuvering can be performed concurrently with dynamic formation acquisition by setting
Appendix
A. Integrator Backstepping Methodology
Integrator backstepping is a recursive control design methodology for systems in so-called strict-feedback form. It provides a systematic way of designing Lyapunov functions and nonlinear controllers for systems of any order. Unlike the feedback linearization method, backstepping can accommodate model uncertainties and avoid the unnecessary cancellation of "useful" (stabilizing) nonlinearities.
Since the dynamic model of the individual agents here have at most order two, we illustrate the backstepping technique by considering the system
where
Notice that the above system is a cascaded connection of subsystems
As a result, our system becomes
Now, if we design
where
we get the closed-loop system
whose unique equilibrium point is
and taking its time derivative along
From Corollary 1.1, we can conclude that
- Marcio de Queiroz, Xiaoyu Cai, and Matthew Feemster, *Formation Control of Multi-Agent Systems: A Graph Rigidity Approach. USA: John Wiley & Sons, Ltd, 2019. Accessed: Dec. 31, 2025:
Section 2 & 3, Appendix C.
The control could also be a function of other, nonposition-related variables depending on the agent model and formation problem being solved. ↩︎
Although the argument of the rigidity matrix function is commonly written as q, it is obvious from
and that is dependent on only. Henceforth, we write so it is clear that the matrix is a function of the relative position. ↩︎ The variable
in $ denotes the basic formation acquisition control term that will be embedded in all control algorithms. ↩︎ Recall from the statement of the formation maneuvering problem in Section 1 that agent
serves as the reference point through which the rotation axis passes. Therefore, in is the relative position between each agent and agent . ↩︎ The introduction of the term
in is crucial for the following stability analysis of the target interception error since it allows to have the simple form in . ↩︎ It is important to point out that the framework
is required to be infinitesimally and minimally rigid for all time. ↩︎ Since the precise smoothness properties are agent model-dependent, they will be specified later. ↩︎